Laravel 数据库性能优化实战(八):一对多关联查询排序实现和性能优化
介绍完一对一和多对一,我们接着来看一对多关联查询中如何基于关联模型字段进行排序。
基于左连接查询实现关联排序
在 UserController 的 index 方法中新增对文章发布时间排序字段的支持,还是先通过左连接查询实现:
public function index()
{
$sort = request()->get('sort');
$query = User::select(['id', 'name', 'email', 'company_id']);
switch ($sort) {
case 'github':
// 基于 Github 用户名排序
$query = $query->orderBy(
Github::select('name')
->whereColumn('user_id', 'users.id')
->orderBy('name')
->limit(1)
);
break;
case 'company':
// 基于公司名名称排序
$query = $query->orderBy(
Company::select('name')
->whereColumn('id', 'users.company_id')
->orderBy('name')
->limit(1)
);
break;
case 'post':
// 基于文章发布时间排序(逆序)
$query = User::select('users.*')
->leftJoin('posts', 'posts.user_id', '=', 'users.id')
->where('posts.status', Post::STATUS_NORMAL)
->orderByDesc('posts.created_at');
break;
default:
$query = $query->orderBy('id');
break;
}
$users = $query->with(['github', 'company'])->withLastPost()->paginate(20);
return view('user.index', ['users' => $users]);
}
然后在对应的视图模板中新增文章标题字段:
<x-app-layout>
<x-slot name="header">
<h2 class="font-semibold text-xl text-gray-800 leading-tight">
用户列表
</h2>
</x-slot>
<div class="py-12">
<div class="max-w-8xl mx-auto sm:px-6 lg:px-8">
<div class="bg-white overflow-hidden shadow-xl sm:rounded-lg">
<div class="flex justify-center">
<table class="w-full m-8">
<thead>
<tr>
<th class="px-4 py-2">ID</th>
<th class="px-4 py-2">Name</th>
<th class="px-4 py-2">Email</th>
<th class="px-4 py-2">Github Account</th>
<th class="px-4 py-2">Company Name</th>
<th class="px-4 py-2">Last Created</th>
</tr>
</thead>
<tbody>
@foreach ($users as $user)
<tr>
<td class="border px-4 py-2">{{ $user->id }}</td>
<td class="border px-4 py-2">{{ $user->name }}</td>
<td class="border px-4 py-2">{{ $user->email }}</td>
<td class="border px-4 py-2">{{ $user->github->name }}</td>
<td class="border px-4 py-2">{{ $user->company->name }}</td>
<td class="border px-4 py-2">
{{ $user->lastPost->title}}
({{ $user->lastPost->created_at->diffForHumans() }})
</td>
</tr>
@endforeach
</tbody>
</table>
</div>
<div class="max-w-full m-8">
{{ $users->withQueryString()->links() }}
</div>
</div>
</div>
</div>
</x-app-layout>
这样一来,在用户列表中就可以看到用户最新发布的文章和发布时间了:
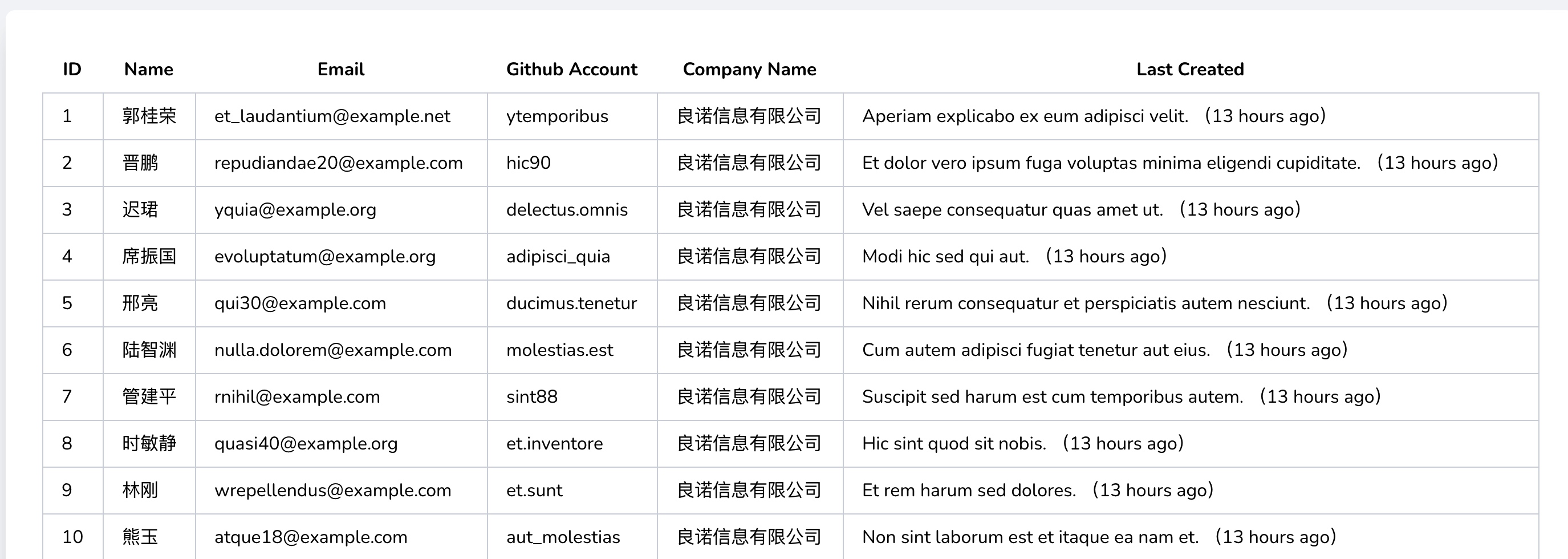
在 URL 请求参数中设置 sort=post 应用文章发布时间排序,按照之前的实现逻辑,现在出现了一个 bug —— 用户列表出现重复的用户记录:
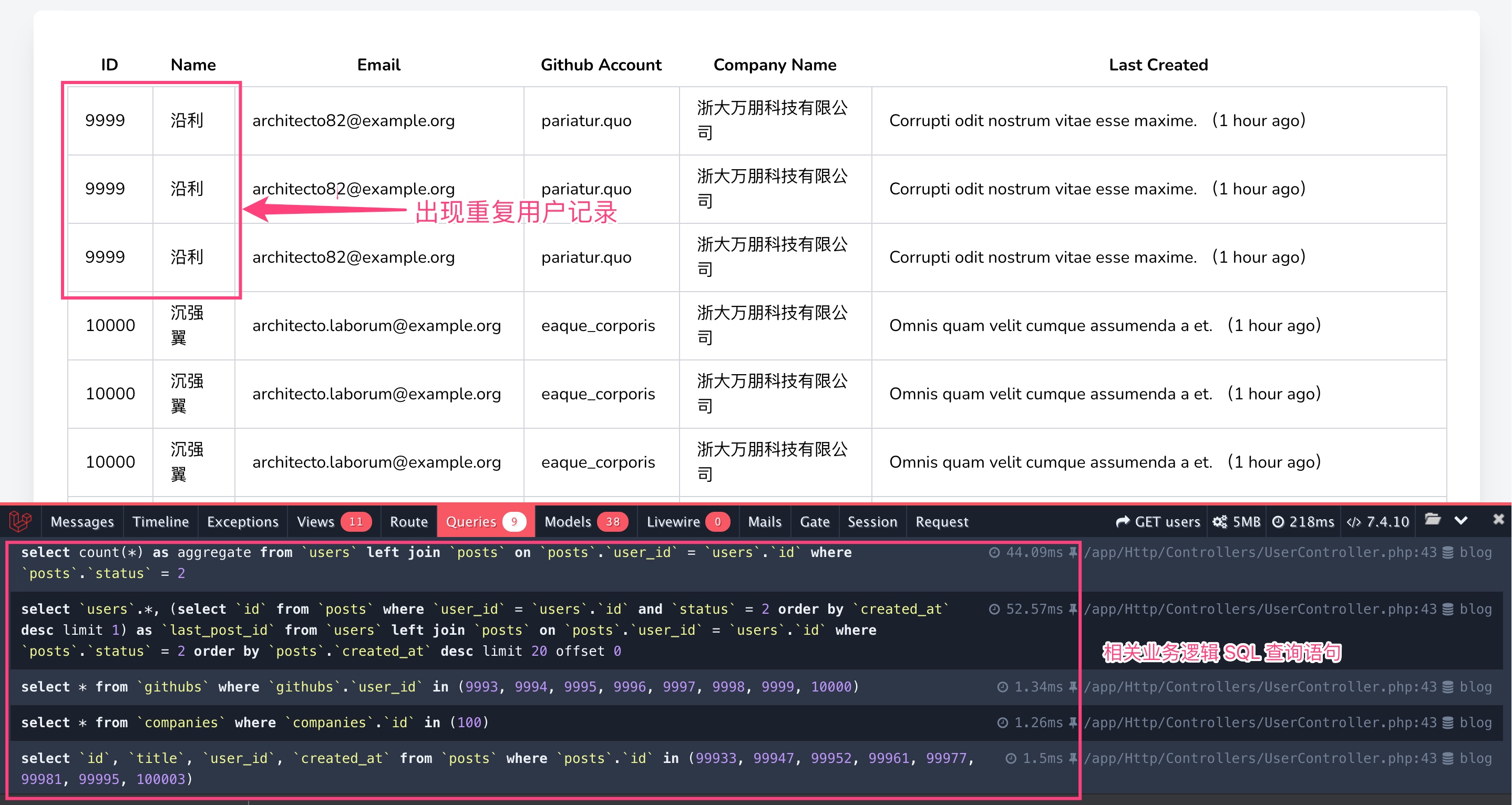
我们将其对应的分页排序 SQL 查询语句拷贝出来,放到 MySQL 客户端 GUI 工具中执行和调试。之所以出现重复记录,是因为用户和文章记录之间是一对多关联,进行左连接查询的时候,会将同一个用户对应的多个文章作为多条记录返回,而对应的用户记录字段会填充相同的数据。
要解决这个问题,需要对相同的用户记录做分组进行去重,同时还要在排序字段中使用 max 函数获取当前分组中的最新(大)的创建时间,否则 MySQL 默认获取当前分组第一条记录的时间,它不一定是最大值,调整后的 SQL 语句如下,执行这条 SQL 语句,就可以实现去重并按照关联文章最新发布时间进行降序排列了:
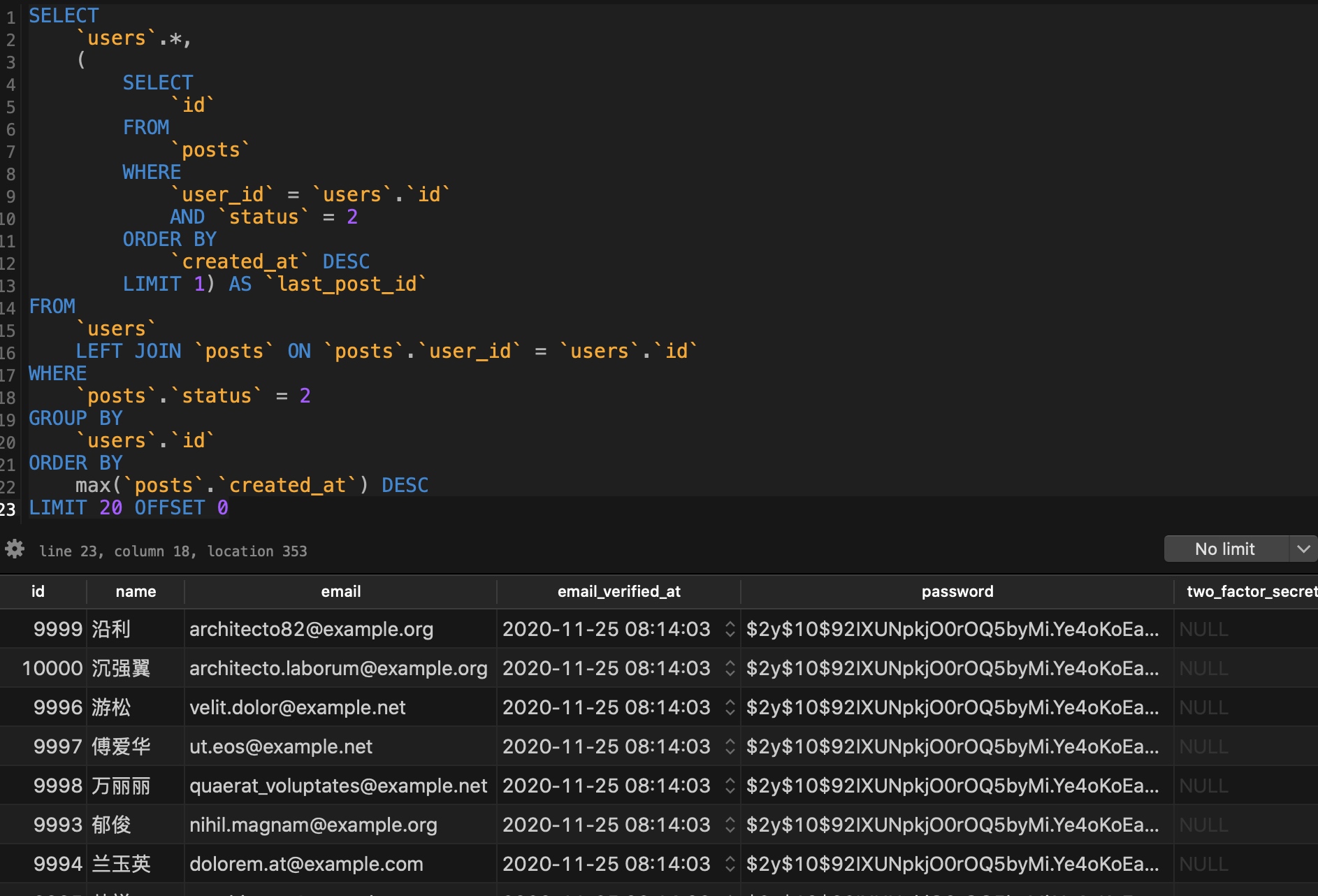
不过,这条语句虽然可以正常运行了,还要通过 explain 命令分析其执行计划,看看是否可以通过索引进行优化:

可以看到该查询语句在做连接查询时会对 posts 表做全表扫描,而 posts 表有 10 万行记录,并且随着时间的推移,这张业务表越来越大,查询效率会越来越低。而在整个存在分组、排序、函数调用的连接查询中,还涉及到创建临时表和文件排序的耗时操作,所以可想而知这条 SQL 的查询效率了。
我们暂时不做索引优化,因为存在函数调用,也不好直接对 created_at 字段加索引,先参照上述 SQL 语句修改业务代码中的 Eloquent 关联排序查询实现如下:
case 'post':
$query = User::select('users.*')
->leftJoin('posts', 'posts.user_id', '=', 'users.id')
->where('posts.status', Post::STATUS_NORMAL)
->groupBy('users.id')
->orderByRaw('max(posts.created_at) DESC');
break;
刷新用户列表,就可以看到现在不会出现重复的用户记录了:
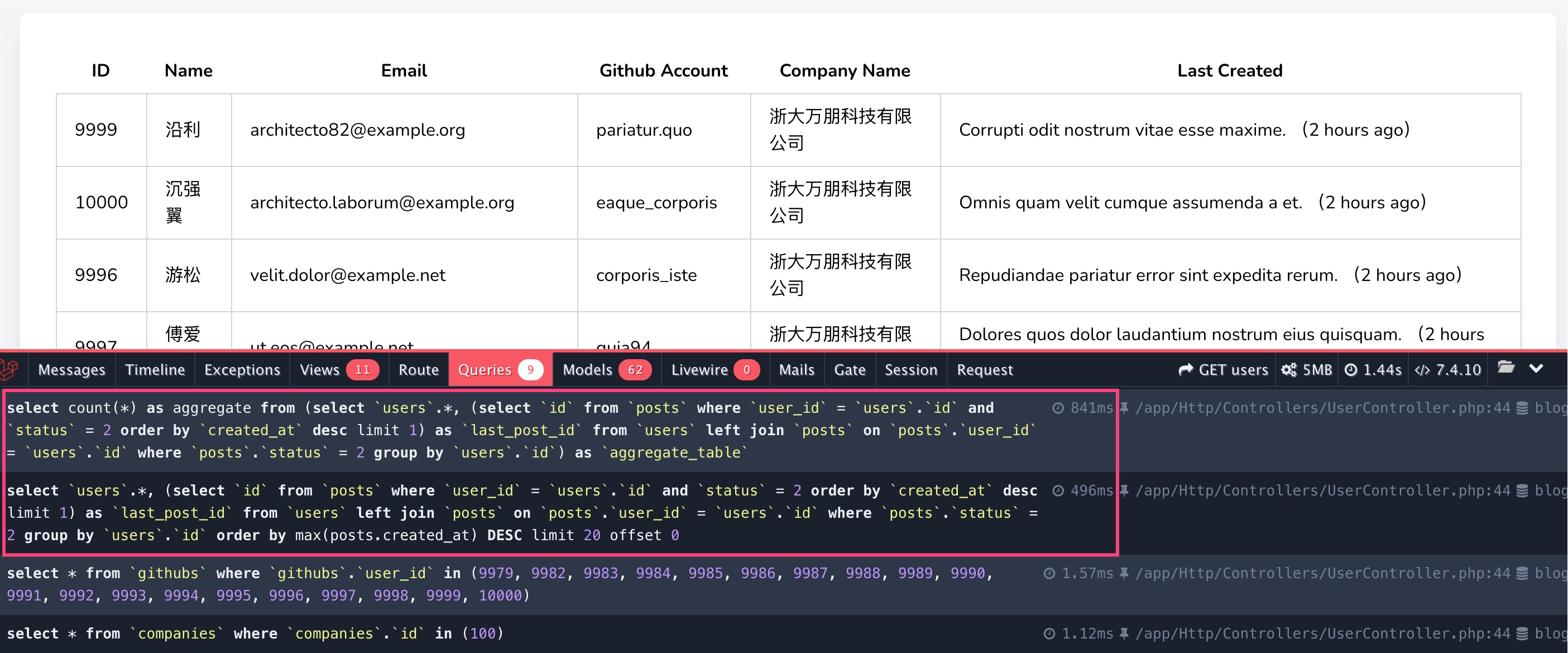
不过功能是实现了,但是性能着实感人,一次聚合统计查询 + 一次分页排序查询耗时接近 1.5s,几乎是慢查询无疑了。
通过子查询进行优化
下面我们参照之前的思路,通过子查询来优化上述关联排序的性能。
注:内连接在一对多关联中不能使用了,因为如果一个用户没有发布过文章,这个用户记录不会出现在结果列表中,属于程序 bug 了。
将上述左连接查询代码调整为子查询实现如下:
$query = $query->orderByDesc(
Post::select('created_at')
->whereColumn('user_id', 'users.id')
->where('status', Post::STATUS_NORMAL)
->orderByDesc('created_at')
->limit(1)
);
可以看到查询性能得到显著优化:

我们分析这个分页排序查询语句的执行计划:
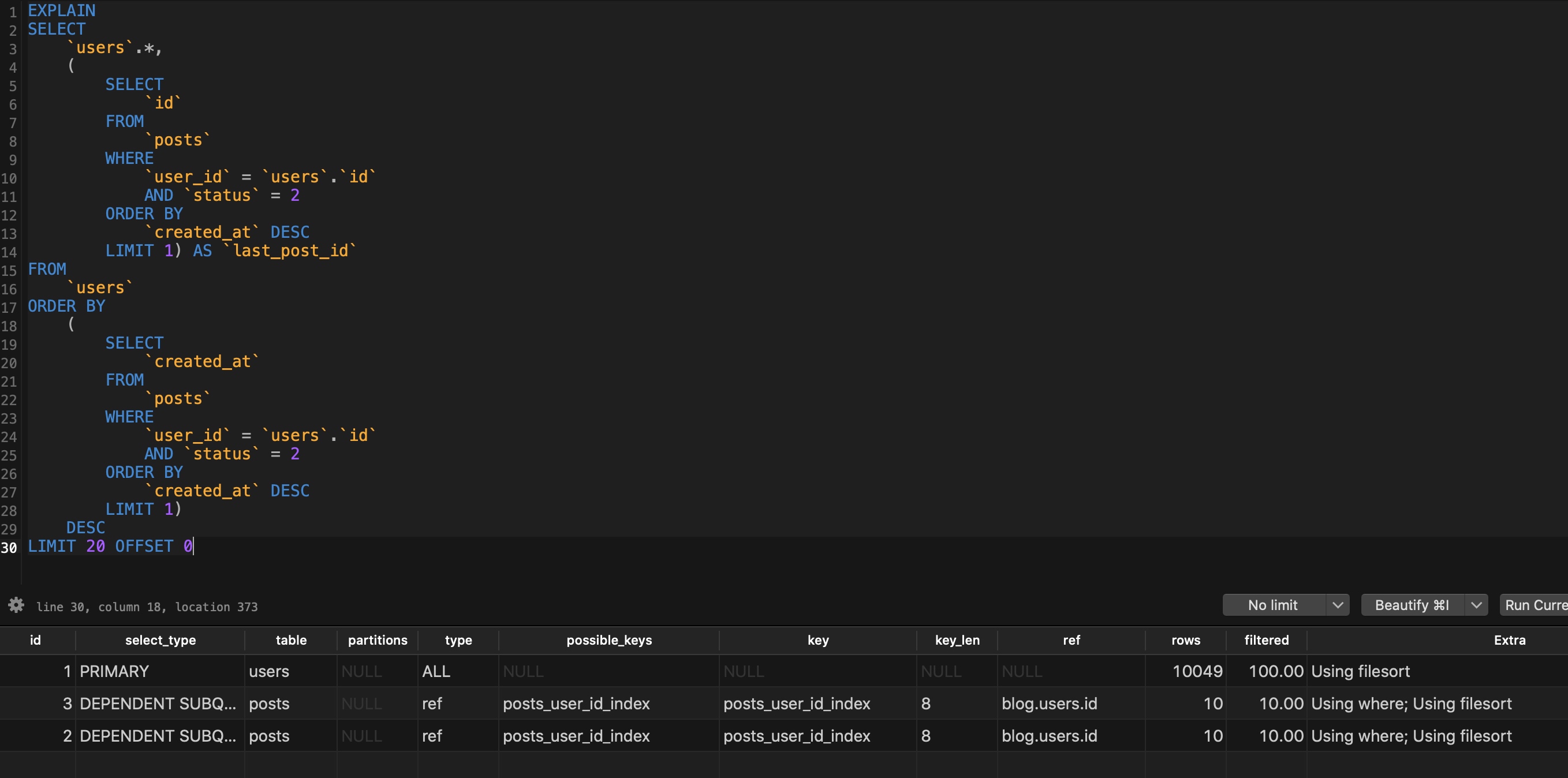
虽然也是全表扫描,但是子查询的时候不会再对 posts 表做全表扫描,而是对 users 表做全表扫描,后者比前者小很多,而且也不涉及临时表的创建,所以性能得到优化。但是如果 users 表和 posts 表都达到百万、千万级呢?这还是会产生慢查询,而且也无法提供过索引对其进行优化。
当然,我们设想的这个查询场景本身就很古怪,如果真要实现类似的功能,不如新建一个活动表,单独存储用户新增文章的活动记录,对于那些数据量很大的表,做子查询和连接查询时要慎之又慎,一不小心就可能会产生慢查询,与其炫技编写复杂 SQL 语句的技能,我觉得倒不如在设计之初就老老实实通过冗余字段、冗余表的方式存储那些热点数据,然后再通过一些简单的、易于优化的 SQL 语句来查询这些数据。
简单不代表低级,通过高级的设计让后续维护变得简单,反而是最酷的事情。
好了,言归正传,性能不行归不行,到底是比左连接要好一些了。下面我们通过 Eloquent 模型类支持的本地查询作用域来重构所有关联排序代码,以便提高代码复用性,对控制器体量做「瘦身」。
通过本地查询作用域重构代码
在 User 模型类中新增如下作用域方法(将 UserController 控制器中相关排序实现代码迁移过来):
public function scopeOrderByGithubName($query, $direction = 'asc')
{
return $query->orderBy(
Github::select('name')
->whereColumn('user_id', 'users.id')
->limit(1)
, $direction);
}
public function scopeOrderByCompanyName($query, $direction = 'asc')
{
return $query->orderBy(
Company::select('name')
->whereColumn('id', 'users.company_id')
->limit(1)
, $direction);
}
public function scopeOrderByPostCreated($query, $direction = 'desc')
{
return $query->orderBy(
Post::select('created_at')
->whereColumn('user_id', 'users.id')
->where('status', Post::STATUS_NORMAL)
->orderBy('created_at', $direction)
->limit(1)
, $direction);
}
然后将 UserController 的 index 方法重构如下(通过 Eloquent 查询构建器提供的 when 方法取代之前的 switch 分支代码,然后调用本地作用域方法实现排序查询):
public function index()
{
$sort = request()->get('sort');
$direction = request()->get('direction') ? : 'asc';
$users = User::select(['id', 'name', 'email', 'company_id'])
->when($sort === 'github', function ($query) use ($direction) {
$query->orderByGithubName($direction);
})->when($sort === 'company', function ($query) use ($direction) {
$query->orderByCompanyName($direction);
})->when($sort === 'post', function ($query) use ($direction) {
$query->orderByPostCreated($direction);
})->with(['github', 'company'])->withLastPost()->paginate(20);
return view('user.index', ['users' => $users]);
}
是不是简洁、干净了许多?
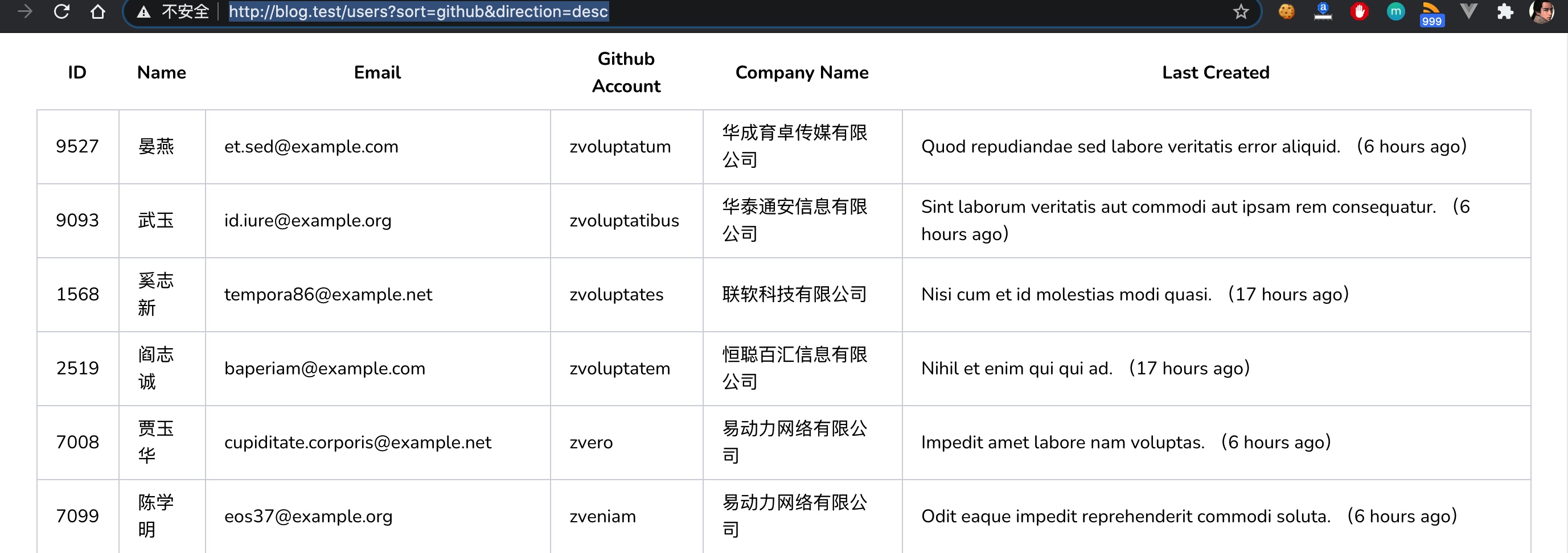
现在我们就可以在用户列表 URL 请求参数中通过 sort 和 direction 参数来设置排序逻辑和升降序了:
小结
好了,关于 Laravel 数据库查询性能优化实战系列到这里就告一段落了,虽然这里面介绍了很多复杂场景下 SQL 查询语句的编写和优化,主要是连接查询和子查询,但是学院君个人更倾向业务前期通过设计让数据库查询语句的编写和优化变得简单,而不是一开始不怎么设计,后期需要通过编写大量复杂的查询语句才能获取数据实现功能,再去优化这些复杂的 SQL 语句,尤其是是业务数据越来越多,越来越复杂的时候,使用子查询和连接查询性能会成倍降低,而且变得难以优化,所以优先去优化表结构和存储逻辑,而不是让 SQL 语句变得越来越复杂。
无评论