进阶篇(一):通过查询构建器实现复杂的查询语句
在上一篇教程中,我们通过查询构建器实现了简单的增删改查操作,而日常开发中,往往会涉及到一些更复杂的查询语句,比如连接查询、子查询、排序、分页、聚合查询等等,这一篇教程我们将围绕这些内容展开探讨。
查询小技巧
我们首先来介绍几个 Laravel 自带的语法糖,可以帮助我们快速获取期望的查询结果,提高编码效率。
有时候,我们想要获取的并不是一行或几行记录,而是某个字段的值,你当然你可以查询到一行记录后从结果对象中获取指定字段的值,但是 Laravel 为我们提供了更便捷的语法:
$name = '学院君';
$email = DB::table('users')->where('name', $name)->value('email');
这样,通过 value 方法返回的就是指定字段的值,无需做额外的判断和提取操作。
如果你想要判断某个字段值在数据库中是否存在对应记录,可以通过 exists 方法快速实现:
$exists = DB::table('users')->where('name', $name)->exists();
如果存在,返回 true,否则返回 false。该方法还有一个与之相对的方法 doesntExist()。
你一定有过这样的经历,从数据库获取指定查询结果后,以主键 ID 值为键,以某个字段值为值构建关联数组,以前,你可能不得不遍历查询结果构建数组才能解决这样的问题,在 Laravel 中,我们只需在查询构建器上调用 pluck 方法即可:
$users = DB::table('users')->where('id', '<', 10)->pluck('name', 'id');
该查询返回的结果如下:
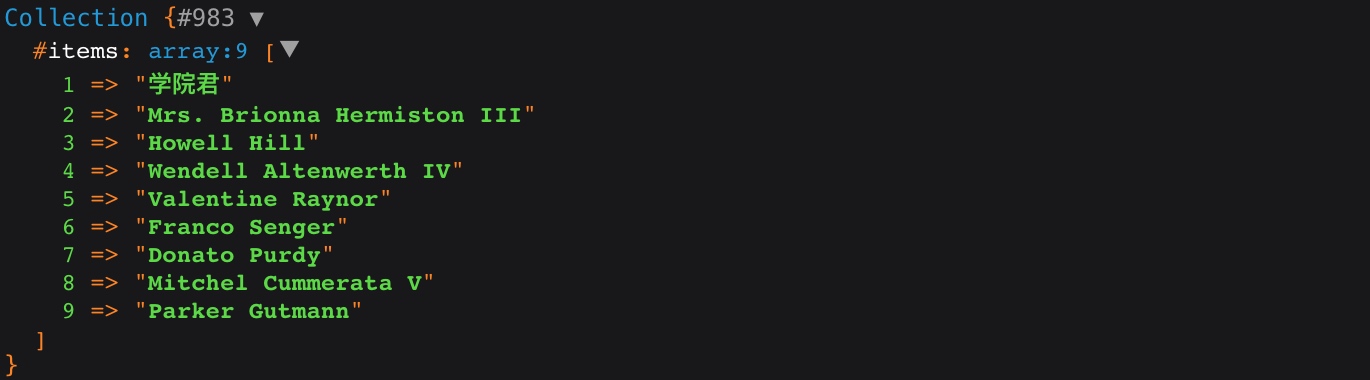
注意,我们在传递参数到 pluck 方法的时候,键对应的字段在后面,值对应的字段在前面。
此外,有的时候,我们从数据库返回的结果集比较大,一次性返回进行处理有可能会超出 PHP 内存限制,这时候,我们可以借助 chunk 方法将其分割成多个的组块依次返回进行处理:
$names = [];
DB::table('users')->orderBy('id')->chunk(5, function ($users) use (&$names) {
foreach ($users as $user) {
$names[] = $user->name;
}
});
以上代码的意思是对 users 按照 id 字段升序排序,然后将获取的结果集每次返回5个进行处理,将用户名依次放到 $names 数组中。打印 $names,结果如下:
聚合函数
在开发后台管理系统时,经常需要对数据进行统计、求和、计算平均值、最小值、最大值等,对应的方法名分别是 count、sum、avg、min、max:
$num = DB::table('users')->count(); # 计数 9
$sum = DB::table('users')->sum('id'); # 求和 45
$avg = DB::table('users')->avg('id'); # 平均值 5
$min = DB::table('users')->min('id'); # 最小值 1
$max = DB::table('users')->max('id'); # 最大值 9
高级 Where 查询
前面我们已经用到过通过 where 方法构建查询子句,这里我们将系统介绍 WHERE 查询子句的各种构建。
基本查询
基本查询
最基本的 WHERE 查询子句就是通过 where 方法进行简单查询了:
DB::table('posts')->where('views', 0)->get(); # 此处等号可以省略
DB::table('posts')->where('views', '>', 0)->get();
DB::table('posts')->where('views', '<>', 0)->get();
第一个参数表示字段名,第二个参数表示运算符(支持SQL所有运算符),第三个参数表示比较值。
like查询
有时候我们可能会对字段进行模糊查询,尤其是字符串匹配的时候:
DB::table('posts')->where('title', 'like', 'Laravel学院%')->get();
and查询
如果有多个 WHERE 条件怎么办?在查询构建器中,可以通过方法链轻松搞定:
DB::table('posts')->where('id', '<', 10)->where('views', '>', 0)->get();
上述代码表示获取 where id < 10 and views > 0 的数据库记录,更多的条件用更多的 where 方法即可。此外,我们还可以通过传入数组参数的方式实现上述代码同样的功能:
DB::table('posts')->where([
['id', '<', 10],
['views', '>', 0]
])->get();
or查询
在日常查询中,or 条件的查询也很常见,在查询构建器中,可以通过 orWhere 方法来实现:
DB::table('posts')->where('id', '<', 10)->orWhere('views', '>', 0)->get();
上述代码表示获取 where id < 10 or views > 0 的数据库记录,多个 and 查询可以通过多个 where 方法连接,同理,多个 or 查询也可以通过多个 orWhere 方法连接。
between查询
在一些涉及数字和时间的查询中,BETWEEN 语句可以排上用场,用于获取在指定区间的记录。在查询构建器中,我们可以通过 whereBetween 方法来实现 between 查询:
DB::table('posts')->whereBetween('views', [10, 100])->get();
上述代码表示获取 where view between 10 and 100 的数据库记录。与之相对的还有一个 whereNotBetween 方法,用于获取不在指定区间的数据库记录:
DB::table('posts')->whereNotBetween('views', [10, 100])->get();
对应的 WHERE 条件是 where views not between 10 and 100。
你可以看出来 between 语句是可以通过 and/or 查询来替代的,只不过使用 between 语句会更简单明了。
in查询
IN 查询也很常见,比如我们需要查询的字段值是某个序列集合的子集的时候。IN 查询可以通过 whereIn 方法来实现:
DB::table('posts')->whereIn('user_id', [1, 3, 5, 7, 9])->get();
对应的 WHERE 子句是 where user_id in (1, 3, 5, 7, 9)。使用该方法时,需要注意传递给 whereIn 的第二个参数不能是空数组,否则会报错。
同样,与之相对的,还有一个 whereNotIn 方法,表示与 whereIn 相反的查询条件。将上述代码中的 whereIn 方法改为 whereNotIn,对应的查询子句就是 where user_id not in (1, 3, 5, 7, 9)。
null查询
NULL 查询就是判断某个字段是否为空的查询,Laravel 查询构建器为我们提供了 whereNull 方法用于实现该查询:
DB::table('users')->whereNull('email_verified_at')->get();
对应的 WHERE 查询子句是 where email_verified_at is null,同样,该方法也有与之相对的 whereNotNull 方法,例如,要进行 where email_verified_at is not null 查询,可以这么实现:
DB::table('users')->whereNotNull('email_verified_at')->get();
日期查询
关于日常查询,查询构建器为我们提供了丰富的方法,从年月日到具体的时间都有覆盖:
DB::table('posts')->whereYear('created_at', '2018')->get(); # 年
DB::table('posts')->whereMonth('created_at', '11')->get(); # 月
DB::table('posts')->whereDay('created_at', '28')->get(); # 一个月的第几天
DB::table('posts')->whereDate('created_at', '2018-11-28')->get(); # 具体日期
DB::table('posts')->whereTime('created_at', '14:00')->get(); # 时间
上面这几个方法同时还支持 orWhereYear、orWhereMonth、orWhereDay、orWhereDate、orWhereTime。
字段相等查询
有的时候,我们并不是在字段和具体值之间进行比较,而是在字段本身之间进行比较,查询构建器提供了 whereColumn 方法来实现这一查询:
DB::table('posts')->whereColumn('updated_at', '>', 'created_at')->get();
对应的 WHERE 查询子句是 where updated_at > created_at。
JSON查询
从 MySQL 5.7 开始,数据库字段原生支持 JSON 类型,对于 JSON 字段的查询,和普通 where 查询并无区别,只是支持对指定 JSON 属性的查询:
DB::table('users')
->where('options->language', 'en')
->get();
如果属性字段是个数组,还支持通过 whereJsonContains 方法对数组进行包含查询:
DB::table('users')
->whereJsonContains('options->languages', 'en_US')
->get();
DB::table('users')
->whereJsonContains('options->languages', ['en_US', 'zh_CN'])
->get();
高级查询
参数分组
除了以上这些常规的 WHERE 查询之外,查询构建器还支持更加复杂的查询语句,考虑下面这个 SQL 语句:
select * from posts where id <= 10 or (views > 0 and created_at < '2018-11-28 14:00');
貌似我们通过前面学到的方法解决不了这个查询语句的构造,所以我们需要引入更复杂的构建方式,那就是引入匿名函数的方式(和连接查询中构建复杂的连接条件类似):
DB::table('posts')->where('id', '<=', 10)->orWhere(function ($query) {
$query->where('views', '>', 0)
->whereDate('created_at', '<', '2018-11-28')
->whereTime('created_at', '<', '14:00');
})->get();
在这个匿名函数中传入的 $query 变量也是一个查询构建器的实例。这一查询构建方式叫做「参数分组」,在带括号的复杂 WHERE 查询子句中都可以参考这种方式来构建查询语句。
WHERE EXISTS
此外,我们还可以通过查询构建器提供的 whereExists 方法构建 WHERE EXISTS 查询:
DB::table('users')
->whereExists(function ($query) {
$query->select(DB::raw(1))
->from('posts')
->whereRaw('posts.user_id = users.id');
})
->get();
对应的 SQL 语句是:
select * from `users` where exists (select 1 from `posts` where posts.user_id = users.id);
用于查询发布过文章的用户。
子查询
有时候,我们会通过子查询关联不同的表进行查询,考虑下面这个 SQL 语句:
select * from posts where user_id in (select id from users where email_verified_at is not null);
对于这条 SQL 语句,我们可以通过查询构建器提供的子查询来实现:
$users = DB::table('users')->whereNotNull('email_verified_at')->select('id');
$posts = DB::table('posts')->whereInSub('user_id', $users)->get();
除了 IN 查询外,普通的 WHERE 查询也可以使用子查询,对应的方法是 whereSub,但是子查询的效率不如连接查询高,所以我们下面来探讨连接查询在查询构建器中的使用。
连接查询
相关术语
在介绍连接查询之前,你需要对 SQL 的几种连接查询有所了解,SQL 连接查询通常分为以下几种类型:
- 内连接:使用比较运算符进行表间的比较,查询与连接条件匹配的数据,可细分为等值连接和不等连接
- 等值连接(=):如
select * from posts p inner join users u on p.user_id = u.id - 不等连接(<、>、<>等):如
select * from posts p inner join users u on p.user_id <> u.id
- 等值连接(=):如
- 外链接:
- 左连接:返回左表中的所有行,如果左表中的行在右表中没有匹配行,则返回结果中右表中的对应列返回空值,如
select * from posts p left join users u on p.user_id = u.id - 右连接:与左连接相反,返回右表中的所有行,如果右表中的行在左表中没有匹配行,则结果中左表中的对应列返回空值,如
select * from posts p right join users u on p.user_id = u.id - 全连接:返回左表和右表中的所有行。当某行在另一表中没有匹配行,则另一表中的列返回空值,如
select * from posts p full join users u on p.user_id = u.id
- 左连接:返回左表中的所有行,如果左表中的行在右表中没有匹配行,则返回结果中右表中的对应列返回空值,如
- 交叉连接:也称笛卡尔积,不带
where条件子句,它将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积,如果带where,返回的是匹配的行数。如select * from posts p cross join users u on p.user_id = u.id
看文字太抽象,图示就很明了了:
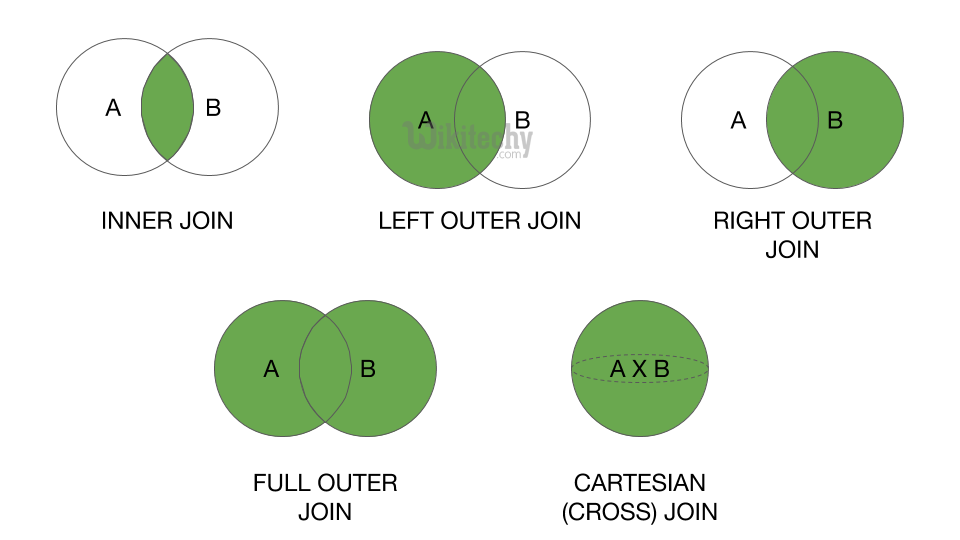
注:在写 SQL 语句时,OUTER 可以省略。
创建并填充 posts 表
为了方便下面的演示,我们新建一个 posts 数据表,首先创建对应迁移文件:
php artisan make:migration create_posts_table --create=posts
编写新增的迁移文件对应迁移类 CreatePostsTable 的 up 方法如下:
public function up()
{
Schema::create('posts', function (Blueprint $table) {
$table->increments('id');
$table->string('title')->comment('标题');
$table->text('content')->comment('内容');
$table->integer('user_id')->unsigned()->default(0);
$table->integer('views')->unsigned()->default(0)->comment('浏览数');
$table->index('user_id');
$table->timestamps();
});
}
运行 php artisan migrate 创建 posts 数据表。然后为该数据表创建一个模型类:
php artisan make:model Post
接下来,我们为这个模型类创建一个模型工厂:
php artisan make:factory PostFactory --model=Post
编写模型工厂 database/factories/PostFactory.php 代码如下:
<?php
use Faker\Generator as Faker;
$factory->define(\App\Post::class, function (Faker $faker) {
return [
'title' => $faker->title,
'content' => $faker->text,
'user_id' => mt_rand(1, 15),
'views' => $faker->randomDigit
];
});
然后为 posts 表创建填充类:
php artisan make:seeder PostsTableSeeder
在 database/seeds 目录下新生成的填充类 PostsTableSeeder 中,调用模型工厂填充数据表:
<?php
use Illuminate\Database\Seeder;
class PostsTableSeeder extends Seeder
{
/**
* Run the database seeds.
*
* @return void
*/
public function run()
{
factory(\App\Post::class, 30)->create();
}
}
这样,我们就可以运行如下 Artisan 命令填充 posts 数据表了:
php artisan db:seed --class=PostsTableSeeder
内连接
首先我们来看内连接在查询构建器中如何实现,以等值连接为例:
$posts = DB::table('posts')
->join('users', 'users.id', '=', 'posts.user_id')
->select('posts.*', 'users.name', 'users.email')
->get();
对照前面的等值连接示例 SQL,很容易理解这段代码,其对应的 SQL 语句是:
select posts.*, users.name, users.email from posts inner join users on users.id = posts.user_id;
在查询构建器中我们通过 join 方法来实现内连接(包含等值连接和不等连接)。上面通过查询构建器查询的结果是:
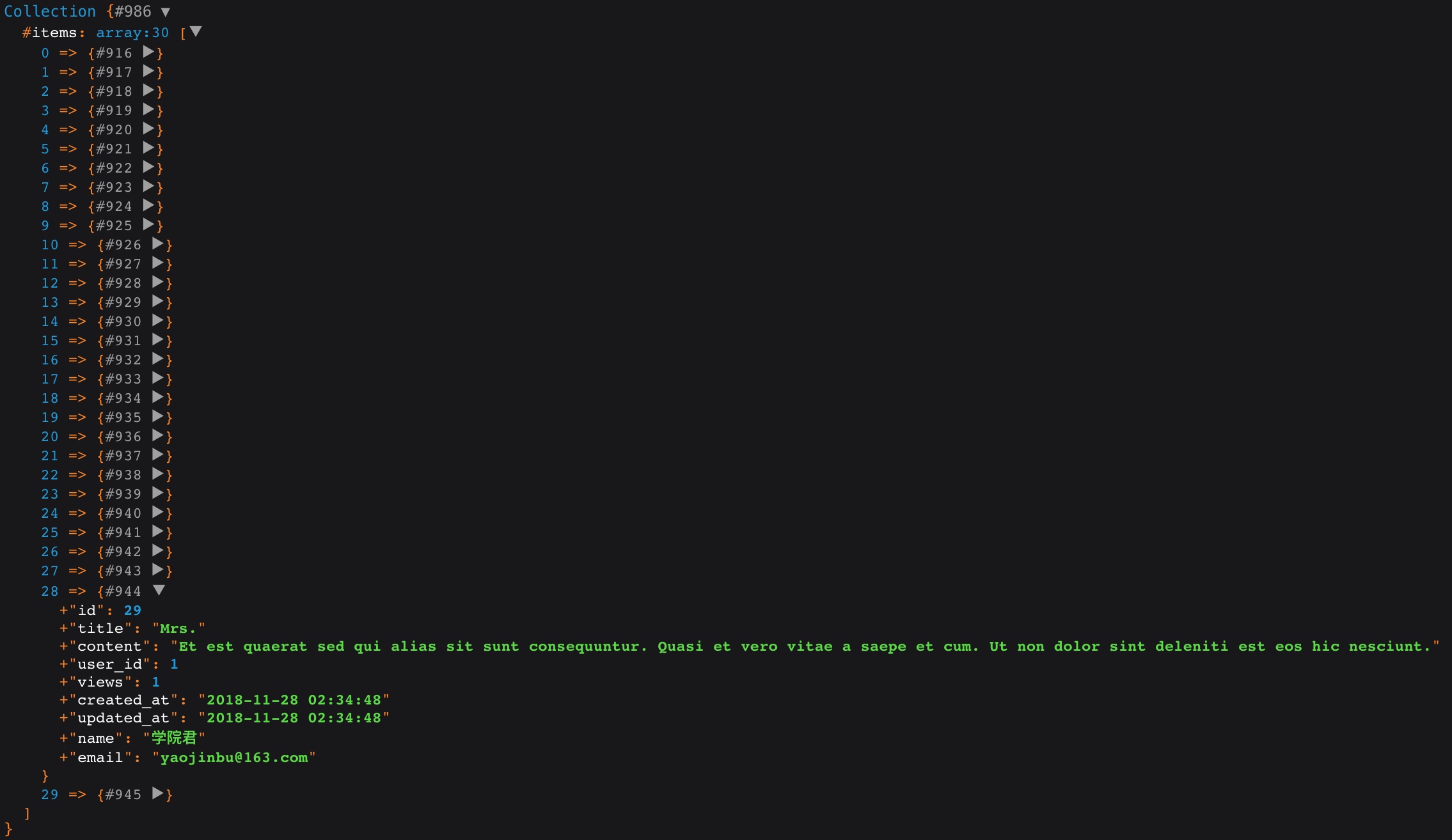
注:当两张表有字段名相同的字段,并且这两个字段都包含在
select方法指定的字段中,需要为其中一个字段取别名,否则会产生冲突,例如,假设posts表中也包含name字段,那么需要为users.name取个别名:select('posts.*', 'users.name as username', 'users.email')。
左连接
左连接也可称作左外连接,在查询构建器中,可以通过 leftJoin 方法实现:
$posts = DB::table('posts')
->leftJoin('users', 'users.id', '=', 'posts.user_id')
->select('posts.*', 'users.name', 'users.email')
->get();
对应的 SQL 语句是:
select posts.*, users.name, users.email from posts left join users on users.id = posts.user_id;
在本例中,由于每个 posts.user_id 都有对应的 users 记录,所以,上述查询结果和等值连接查询结果一致。
右连接
右连接也可称作右外链接,在查询构建器中,可以通过 rightJoin 方法实现:
$posts = DB::table('posts')
->rightJoin('users', 'users.id', '=', 'posts.user_id')
->select('posts.*', 'users.name', 'users.email')
->get();
对应的 SQL 语句如下:
select posts.*, users.name, users.email from posts right join users on users.id = posts.user_id;
在本例中,不是每个用户都有对应的 posts 记录,所以会出现某些 posts 记录为空的结果:

其它连接语句
上面三种是比较常见的连接语句,查询构建器没有提供单独的方法支持全连接,但是有对交叉连接的支持,对应的方法 crossJoin,使用方法如上面几种查询类似,这里不再单独演示了。
更加复杂的连接条件
有时候,你的连接查询条件可能比较复杂,比如下面这种:
select posts.*, users.name, users.email from posts inner join users on users.id = posts.user_id and users.email_verified_at is not null where posts.views > 0;
这个时候,我们可以通过匿名函数来组装连接查询的条件来构建上面的查询语句:
$posts = DB::table('posts')
->join('users', function ($join) {
$join->on('users.id', '=', 'posts.user_id')
->whereNotNull('users.email_verified_at');
})
->select('posts.*', 'users.name', 'users.email')
->where('posts.views', '>', 0)
->get();
我们可以在匿名函数的 $join 实例上调用所有 Where 查询子句,以组装我们需要的连接查询条件。上述查询会将对应用户邮箱未验证的,文章浏览数为 0 的所以结果过滤掉:
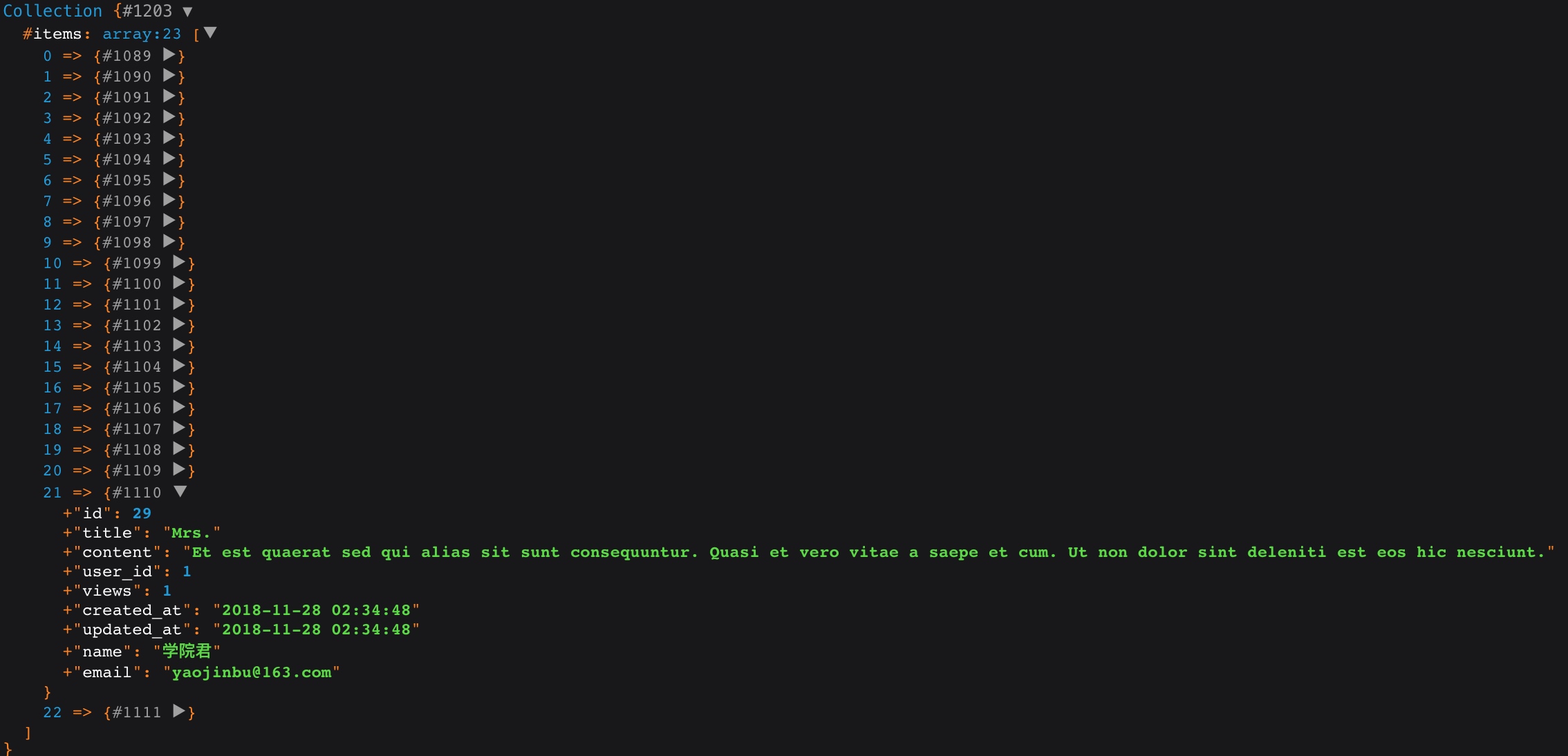
联合查询
查询构建器还支持通过 union 方法合并多个查询结果:
$posts_a = DB::table('posts')->where('views', 0);
$posts_b = DB::table('posts')->where('id', '<=', 10)->union($posts_a)->get();
通过上面这段代码,我们将 views = 0 和 id <= 10 这两个查询结果合并到了一起:
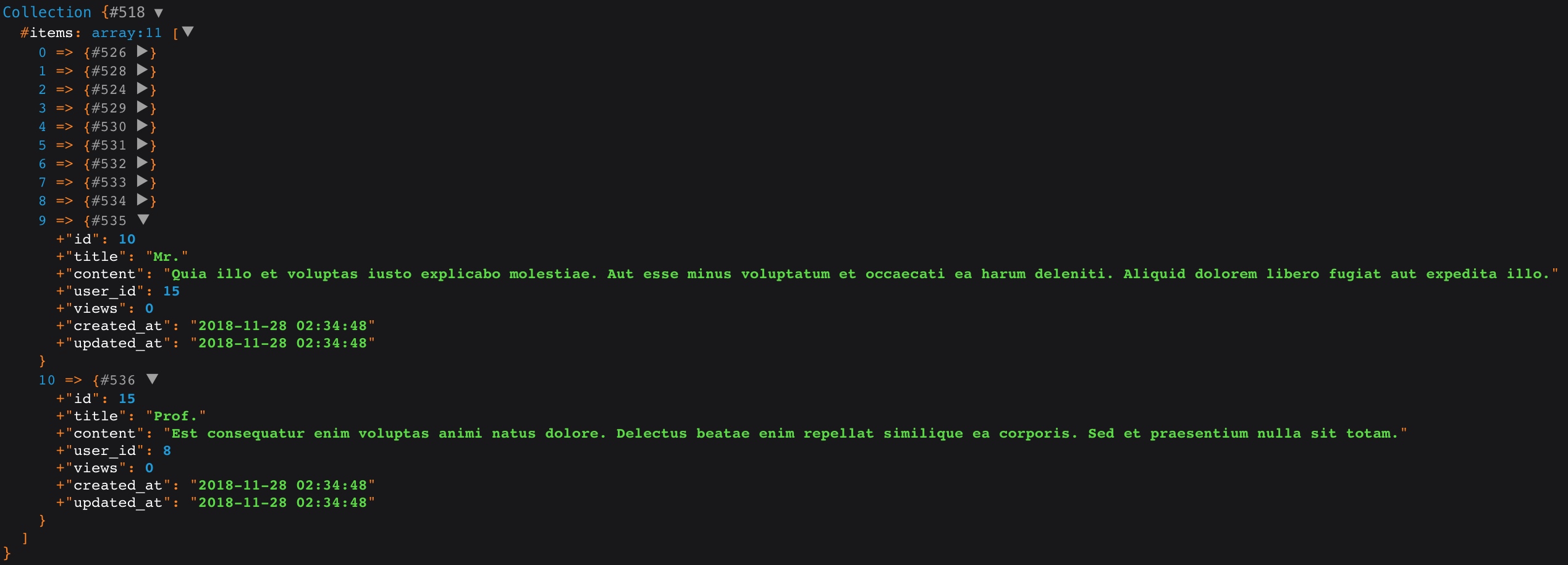
对应的 SQL 语句是:
(select * from `posts` where `id` <= 10) union (select * from `posts` where `views` = 0)
此外,查询构建器也支持 UNION ALL 查询,对应的方法是 unionAll,该方法与 union 的区别是允许重复记录,将上述代码中的 union 方法改为 unionAll,会发现查询结果中包含一条重复记录:
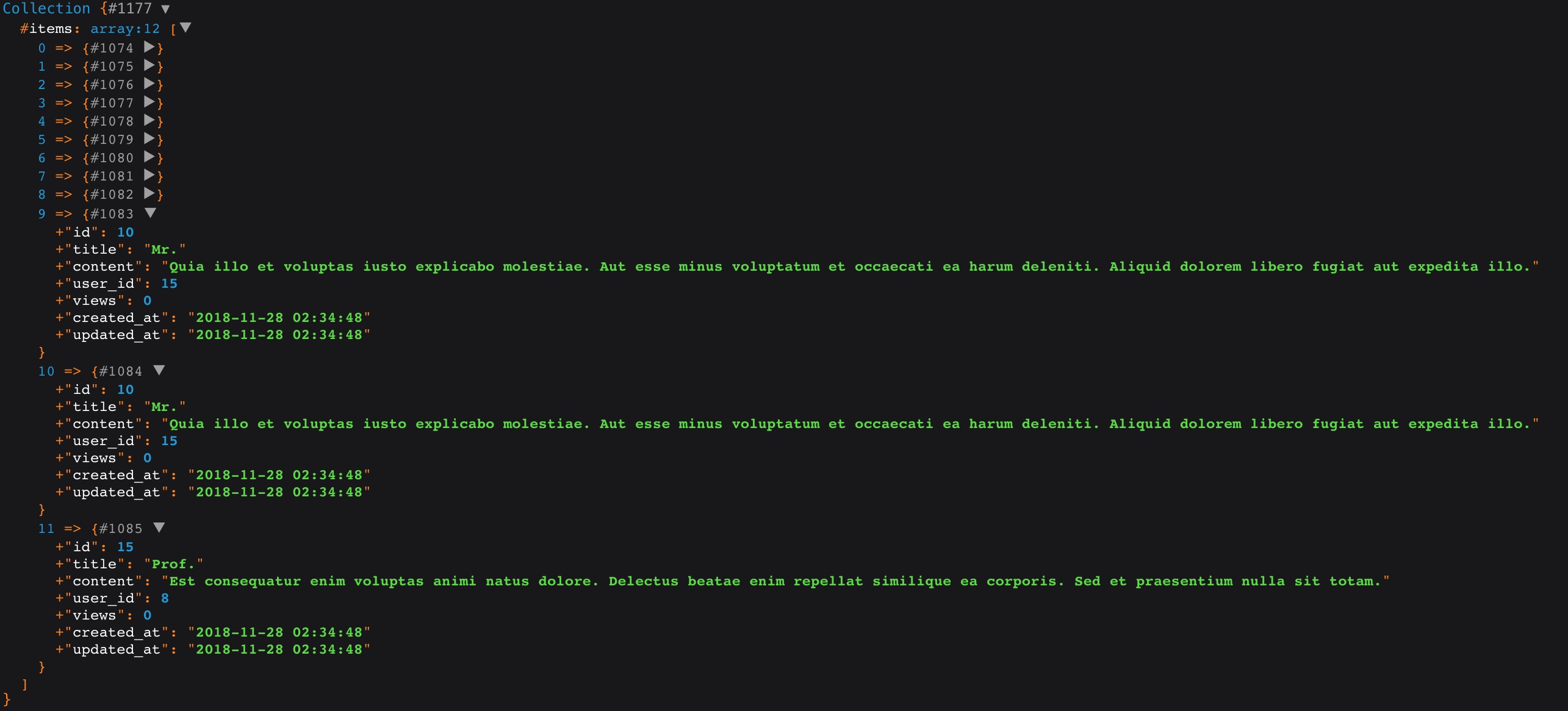
排序
对数据库进行查询免不了对查询结果进行排序,查询构建器为此提供了 orderBy 方法,比如我们想要对文章列表按照创建时间进行逆序排序,可以这么做:
$users = DB::table('posts')
->orderBy('created_at', 'desc')
->get();
对应的 SQL 语句如下:
select * from `posts` order by `created_at` desc;
如果是升序排序,可以这么实现:
DB::table('posts')->orderBy('created_at')->get();
默认排序规则就是升序,所以第二个参数 asc 可以省略。
查询构建器还支持通过 inRandomOrder 方法进行随机排序:
DB::table('posts')->inRandomOrder()->get();
注:对于较小的结果集可以使用随机排序,结果集很大的话不要使用,因为性能比较差。
分组
查询构建器还提供了 groupBy 方法用于对结果集进行分组:
$posts = DB::table('posts')
->groupBy('user_id')
->selectRaw('user_id, sum(views) as total_views')
->get();
上述代码对应的 SQL 语句是:
select user_id, sum(views) as total_views from `posts` group by `user_id`;
用于从 user_id 维度统计每个用户发布文章的总浏览数:
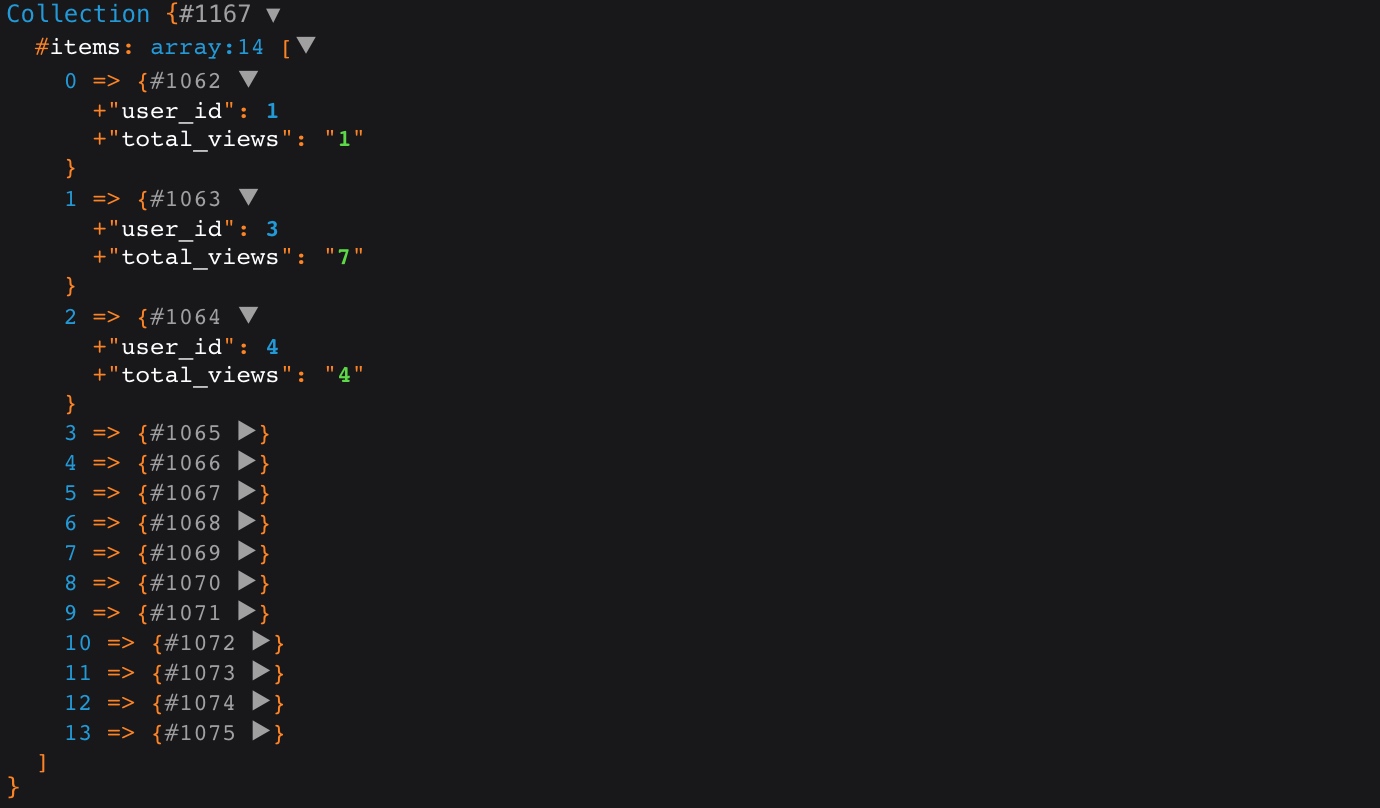
如果我们想要进一步对分组结果进行过滤,可以使用 having 方法,比如,要从上述分组结果中过滤出总浏览数大于等于 10 的记录,可以这么做:
$posts = DB::table('posts')
->groupBy('user_id')
->selectRaw('user_id, sum(views) as total_views')
->having('total_views', '>=', 10)
->get();
对应的 SQL 语句是:
select user_id, sum(views) as total_views from `posts` group by `user_id` having `total_views` >= 10;
对应的查询结果是:

分页
日常开发中,另一个常见的查询场景就是分页查询了,在查询构建器中提供了两种方式来进行分页查询。
第一种是通过 skip 方法和 take 方法组合进行分页,skip 方法传入的参数表示从第几条记录开始,take 传入的参数表示一次获取多少条记录:
$posts = DB::table('posts')->orderBy('created_at', 'desc')
->where('views', '>', 0)
->skip(10)->take(5)
->get();
对应的 SQL 语句是:
select * from `posts` where `views` > 0 order by `created_at` desc limit 5 offset 10;
该查询会先按照查询条件和排序条件进行过滤和排序,然后从第10条记录开始获取5条记录返回。
另一种是通过 offset 方法和 limit 方法组合进行分页查询,offset 表示从第几条记录开始,limit 表示一次获取多少条记录,使用方式和 skip 和 take 类似:
$posts = DB::table('posts')->orderBy('created_at', 'desc')
->where('views', '>', 0)
->offset(10)->limit(5)
->get();
对应的 SQL 语句如下:
select * from `posts` where `views` > 0 order by `created_at` desc limit 5 offset 10;
底层最终执行的 SQL 语句完全一样,所以,随便你选择哪种方式都是可以的。
原生查询
如果上面介绍的构建方式还是不能满足你的需求,无法构建出你需要的 SQL 查询语句,那么可以考虑通过查询构建器提供的原生查询方法来构建查询。
查询构建器提供的原生查询支持请参考官方文档,里面说的比较详细,这里就不再赘述了;如果查询构建器提供的原生方法还不能满足你的需求,那只有使用 DB 门面进行彻底的原生查询操作了。
20 条评论
在“联合查询”一处有个说法似乎错了: 通过上面这段代码,我们将 views < 0 和 id <= 10 这两个查询结果合并到了一起
上面这句话是否应该修正为 “……我们将 views = 0 和……”?
是的 笔误 已修正
辛苦学院君了,这章内容好多,头都看晕了。。。 想问问查询构建起会留下日志可查之类的吗?以前的项目都写原生sql,执行之前先记录下sql方便查错
Telescope 了解下:https://xueyuanjun.com/post/19557.html
感觉不如 ci 的好看啊。
使用通过查询构建器实现复杂的查询语句太麻烦了,而且还不清晰,在企业的生产系统。多表select、update、insert、delete、复杂子查询、存储过程、结合临时表、甚至跨多数据库数据整合等是经常发生的事情。感觉查询构建器有些吃力,繁琐。
学院君,您对laravel比较精通,请问laravel适合生产环境的企业架构系统吗?例如ERP系统、OA系统
高级查询 - 参数分组这里有个疑问
和
用DB::getQueryLog()查看生成出来的语句
日期和时间变成并关系的条件了,2018-11-28之前每天14:00后都被排除掉
应该用下面的处理?
在本例中,不是没有用户都有对应的 posts 记录,所以会出现某些 posts 记录为空的结果:
没有->每个
感谢反馈 已修正