Laravel 数据库性能优化实战(七):一对一和多对一关联查询排序实现和性能优化
基本理论回顾
在前面几篇教程中,学院君已经陆续给大家演示了 Laravel 数据库单表查询、统计查询、关联查询和模糊匹配的性能优化,最后我们再来看看日常开发中比较常见的排序场景性能优化。
当然,关于数据库排序的底层原理和基本优化思路,学院君已经在带分页、排序和分组统计的查询如何使用索引进行优化这篇教程中详细介绍过,对于排序查询,需要在排序字段上设置索引,如果有多个排序字段,还可以通过组合索引进一步优化查询效率。
以用户列表为例,我们现在使用的是带有主键索引的 id 字段进行分页排序:
$users = $query->orderByDesc('id')->paginate(20);
在 Laravel Debugbar 工具条中可以看到查询时间是 1ms 左右:

而如果使用没有设置索引的 created_at 字段进行排序的话:
$users = $query->orderByDesc('created_at')->paginate(20);
对应的查询时间变成了 9ms,慢了近 10 倍!

所以,合理设置索引和组合索引是提升数据库排序查询性能的第一步。
NULL 排序
有的时候,会遇到排序字段包含 NULL 值的情况,比如我们给用户表 users 新增几条 created_at 字段值为 NULL 的记录,如果是按照 created_at 字段降序排序的话,这些记录会放到返回结果的末尾,但如果是升序排序的话,这些记录会出现在返回结果的最前面:
如果你想要设置不管按照 created_at 字段升序还是降序排列,created_at 字段值为 NULL 的记录始终出现在返回结果末尾,可以这么做:
select `id`, `name`, `email`, `company_id`, `created_at` from `users` order by created_at is null, `created_at` asc limit 20 offset 0
对应的 Eloquent 查询代码实现如下:
$users = $query->orderByRaw('created_at is null')
->orderBy('created_at')
->paginate(20);
这样一来,不管怎么排序,created_at 字段值为 NULL 的记录将始终出现在最后面。
模型数据准备
好了,关于排序优化的基本原理就简单回顾到这里,接下来,我们来看看如何基于关联查询进行排序(其实本质上讨论的是连接查询中的复杂排序实现和优化)。
我们从最简单的一对一关联开始。
开始之前,新建一个 Github 模型类用于和 User 模型建立一对一关联:
php artisan make:model Github -m
编写对应的数据库迁移文件如下:
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
class CreateGithubsTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('githubs', function (Blueprint $table) {
$table->id();
$table->string('name')->unique();
$table->bigInteger('user_id')->unsigned()->unique();
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::dropIfExists('githubs');
}
}
githubs 表中只有两个业务字段,name 表示 Github 用户名,user_id 用于和 users 表建立一对一外键关联。
运行 php artisan migrate 创建这个数据表,然后在 Github 模型类中定义一对一关联关系:
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Factories\HasFactory;
use Illuminate\Database\Eloquent\Model;
class Github extends Model
{
use HasFactory;
public function user()
{
return $this->belongsTo(User::class);
}
}
User 模型类中也定义一个相对的关联方法:
public function github()
{
return $this->hasOne(Github::class);
}
接下来,为 Github 模型类创建一个模型工厂:
php artisan make:factory GithubFactory
编写对应的模型工厂代码如下:
<?php
namespace Database\Factories;
use App\Models\Github;
use App\Models\User;
use Illuminate\Database\Eloquent\Factories\Factory;
use Illuminate\Support\Str;
class GithubFactory extends Factory
{
/**
* The name of the factory's corresponding model.
*
* @var string
*/
protected $model = Github::class;
/**
* Define the model's default state.
*
* @return array
*/
public function definition()
{
return [
'name' => $this->faker->unique()->userName,
'user_id' => User::factory()
];
}
}
非常简单,再新建一个填充器用来填充 githubs 数据表:
php artisan make:seeder GithubsSeeder
对应的填充器代码如下:
<?php
namespace Database\Seeders;
use App\Models\Github;
use App\Models\User;
use Illuminate\Database\Seeder;
class GithubsSeeder extends Seeder
{
/**
* Run the database seeds.
*
* @return void
*/
public function run()
{
Github::truncate();
User::chunk(500, function ($users) {
foreach ($users as $user) {
Github::factory(['user_id' => $user->id])->create();
}
});
}
}
由于用户记录已存在,我们基于已存在的用户创建对应的 Github 记录即可。
最后运行 php artisan db:seed --class=GithubsSeeder 填充 githubs 表数据,这样,就做好了模型数据准备工作。
一对一关联查询排序
通过左连接查询实现关联排序
接下来,我们来演示一对一关联排序的实现。
这里我们的业务场景是在用户列表页根据 Github 用户名对所有用户进行升序排序,这可以通过一个左连接查询来实现:
// 代码位于 UserController 控制器中
public function index()
{
$users = User::select('users.*')
->leftJoin('githubs', 'githubs.user_id', '=', 'users.id')
->orderBy('githubs.name')
->with('github')
->paginate(20);
return view('user.index', ['users' => $users]);
}
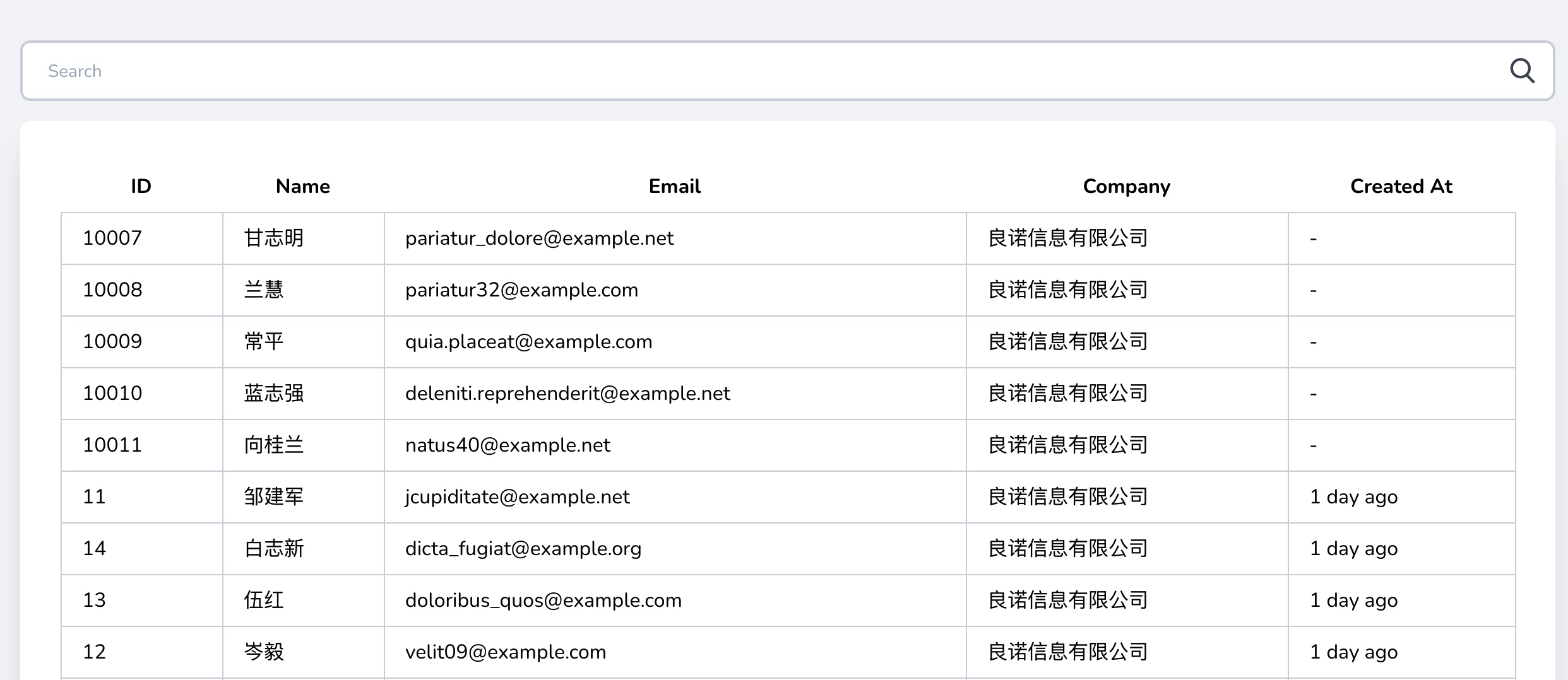
刷新用户列表页,就可以看到根据 Github 用户名升序排列的用户列表了:
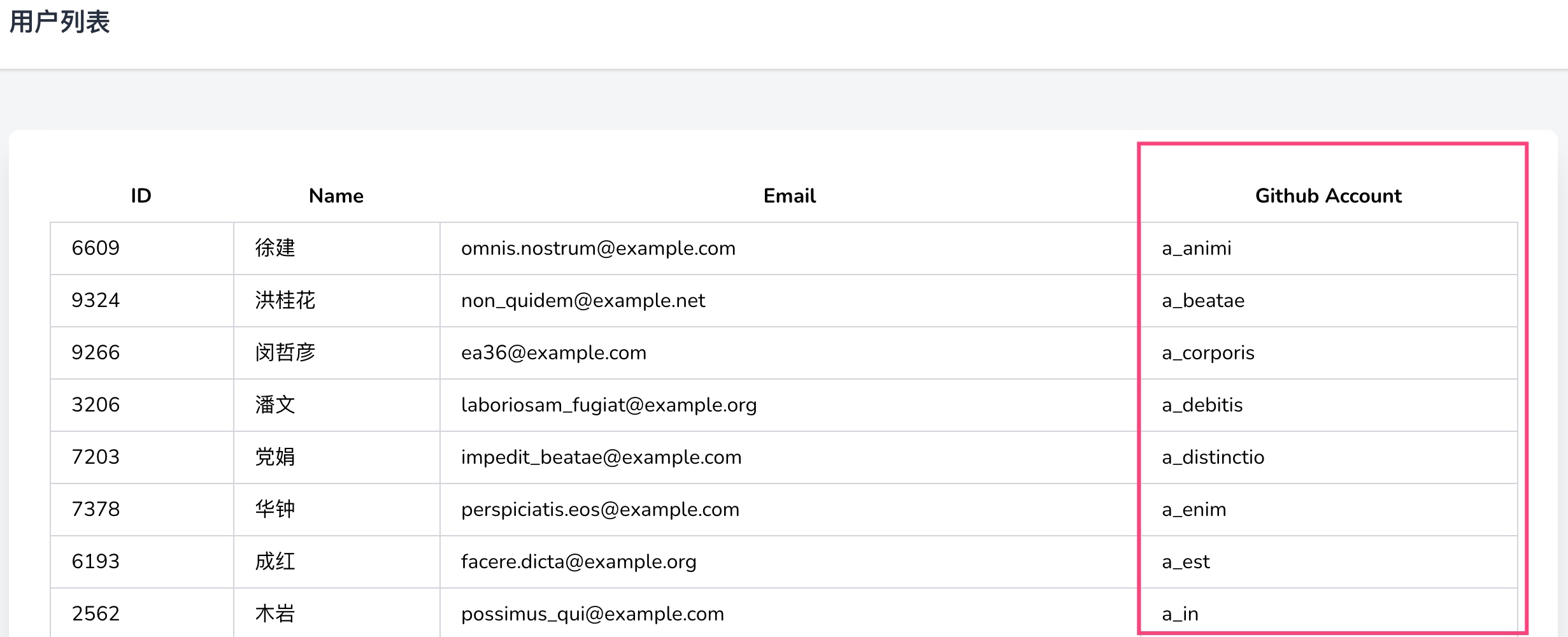
在 Laravel Debugbar 工具条中可以看到对应的 SQL 查询语句:

对于这个包含左连接查询的排序语句,我们通过 explain 命令查看其执行计划,可以看到涉及到对 users 表的全表扫描,并且创建了临时表以及使用了文件排序:
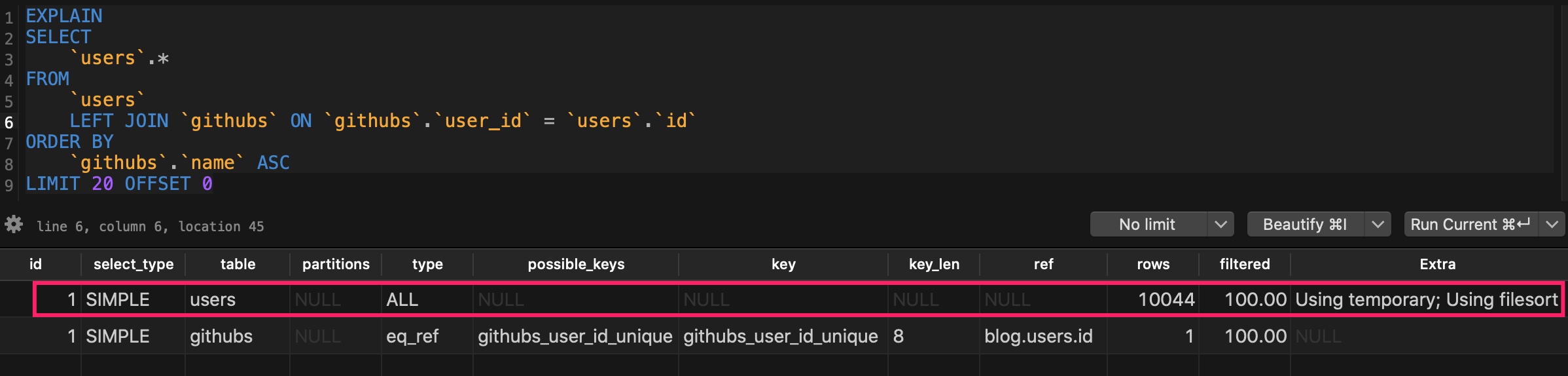
所以尽管排序字段上设置了索引,但是整体查询性能并不高,一次聚合统计+一次分页排序查询就消耗了 100ms 的数据库查询时间。
通过子查询进行优化
除了左连接之外,我们还可以通过子查询实现这个排序功能,对应的 Eloquent 实现代码如下:
$users = User::select(['id', 'name', 'email'])
->orderBy(Github::select('name')
->whereColumn('user_id', 'users.id')
->orderBy('name')
->limit(1)
)
->with('github')
->paginate(20);
注:子查询只能返回一条记录,所以通过
limit进行了限定。
刷新用户列表,效果完全一样:
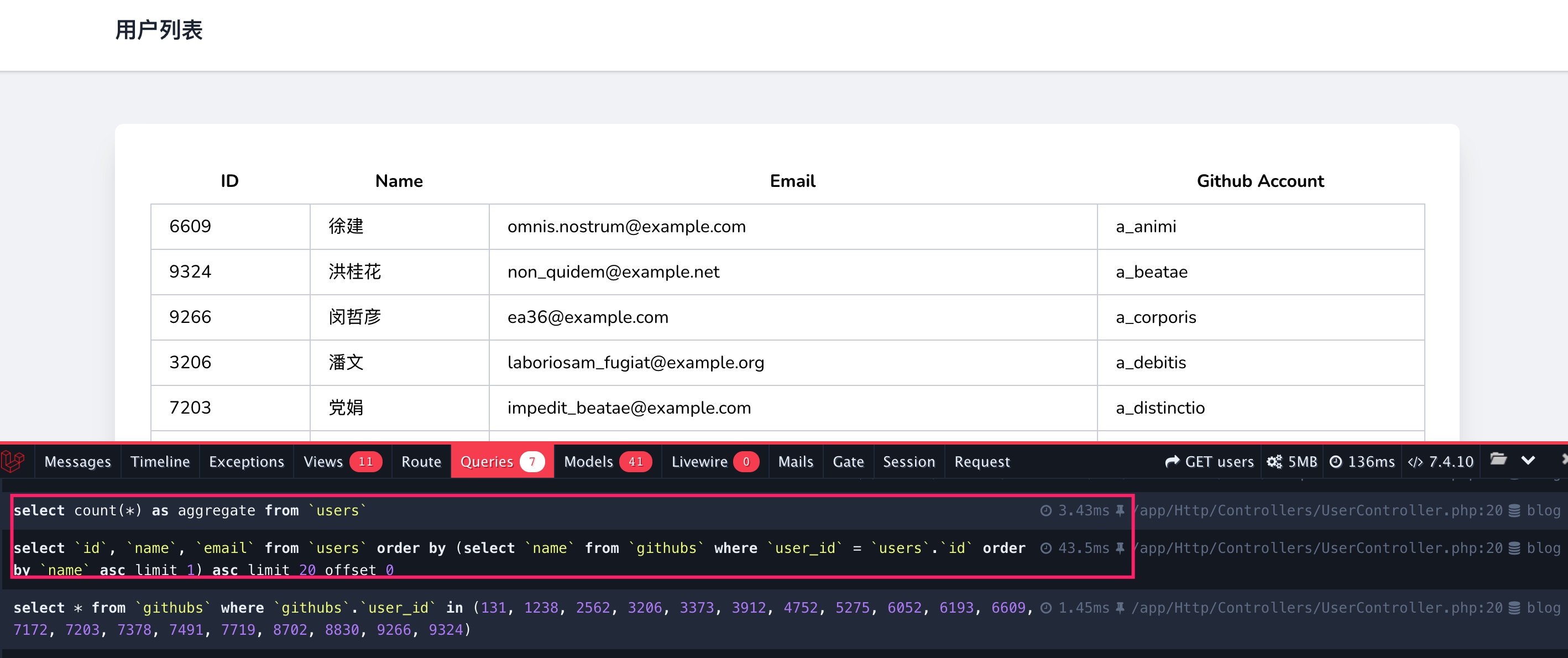
不过我们可以看到查询性能得到了优化,首先是聚合统计,不再包含连接查询,所以耗时很低,然后是包含子查询的分页排序查询,耗时也降低了一半,我们可以通过 explain 语句分析其执行计划:

虽然也要对 users 表做全表扫描,但是这一次没有创建临时表,所以性能得到优化。
注:这并不能得出子查询效率比连接查询效率高的结论,只是在这种场景下比连接查询效率高一点,因为子查询包含非常多的类型,这只是其中比较特殊的行子查询。
通过内连接查询进行优化
不过即便如此,还是不尽如人意,能不能进一步优化这个查询性能呢?
我们知道,连接查询包含内连接、左(外)连接和右(外)连接,如果 users 和 githubs 的所有记录严格一一对应的话,我们还可以通过内连接来优化左连接查询的效率,因为内连接取的是两表的交集,谁是驱动表、谁是被驱动表不影响最终查询结果(外连接则不行),因此,MySQL 底层会根据最优的执行计划来确定谁是驱动表、谁是被驱动表。
对于我们这个查询场景来说,如果选择 githubs 作为驱动表,则只需要根据 name 字段值升序取前 20 行记录,再到被驱动表 users 中获取对应的用户记录返回即可,这个查询将不存在全表扫描,整个扫描行数也只有 20 行。
下面我们将上述左连接查询修改为连接查询来验证下是不是这样:
$users = User::select('users.*')
->join('githubs', 'githubs.user_id', '=', 'users.id')
->orderBy('githubs.name')
->with('github')
->paginate(20);
刷新用户列表,返回结果和前面两种实现一样:
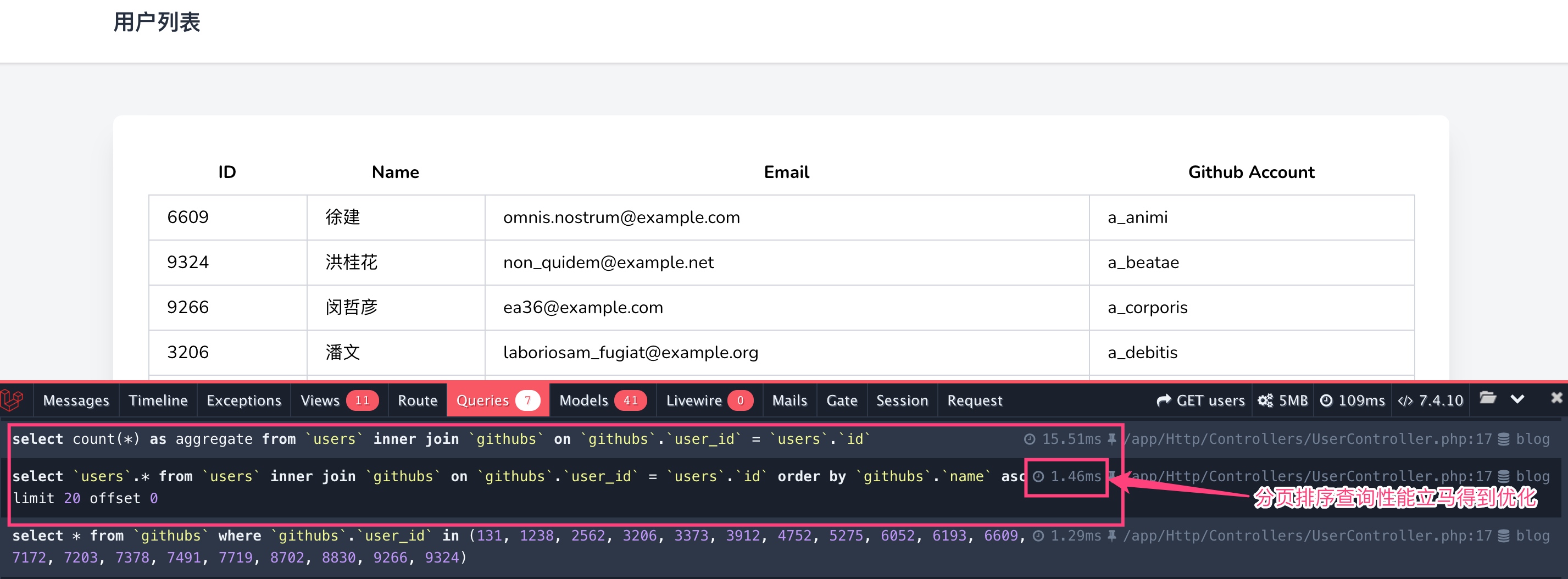
但是可以看到分页排序性能得到了大幅优化,分析其执行计划,可以看到确实如我们所预测的那样,MySQL 底层将 githubs 表作为驱动表,将 users 表作为驱动表,整个查询不涉及全表扫描,都是用上了索引,也不存在临时表创建和文件排序:
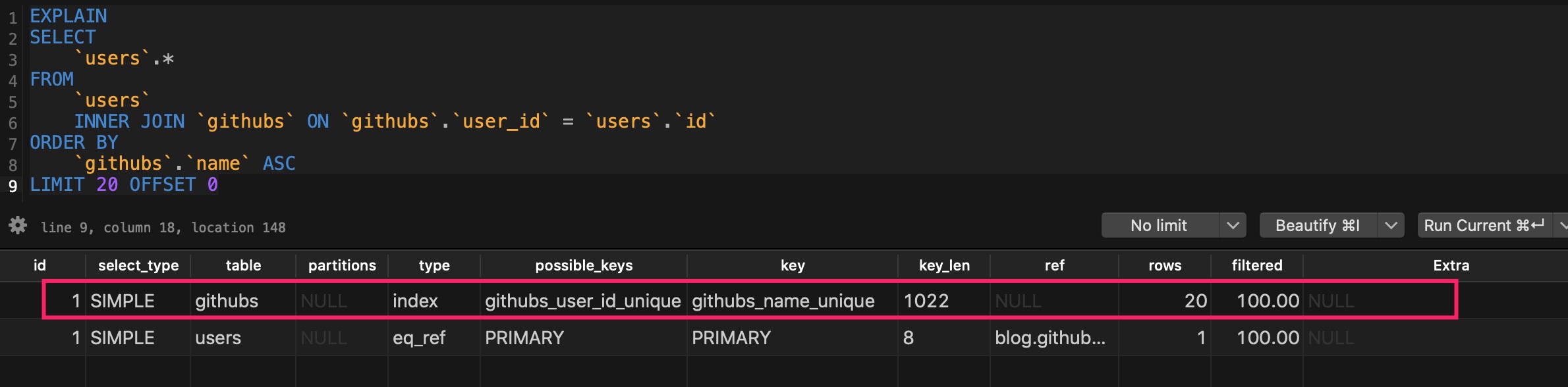
所以,对于这种一对一关联排序,如果两个数据表满足一一对应,使用内连接排序是最优方案,当然,能够使用索引进行优化的话,也不要吝惜设置这个索引,否则还是会进行全表扫描。
注:和子查询一样,这里也不能得出内连接查询效率就一定高于左连接,还是要根据具体场景分析。
归属关联排序
逆向一对一关联排序实现和优化
与一对一关联相对的归属关联排序和上面实现和优化思路一样,只需要将表名和字段调换下就好了,这里不再重复演示了,以内连接为例对应实现代码如下:
$githubs = Github::select('githubs.*')
->join('users', 'users.id', '=', 'githubs.user_id')
->orderBy('users.name')
->with('user')
->paginate(20);
如果是子查询的话对应实现代码如下:
$githubs = Github::orderBy(
User::select('name')
->whereColumn('id', 'githubs.user_id')
->orderBy('name')
->limit(1)
)
->with('user')
->paginate(20);
逆向一对多关联排序实现和优化
与一对多关联相对的关联也是归属(belongsTo)关联,我们以公司和用户的一对多关联进行演示,对于用户而言,每个用户都归属于某个公司,这里的示例场景是在用户列表页实现基于用户所属公司名对用户数据进行分页排序。
我们将用户列表对应的后端控制器方法重构为支持不同的排序字段,这个排序字段由 URL 请求参数 sort 指定,新增一个 sort=company 的排序实现代码如下:
class UserController extends Controller
{
public function index()
{
$sort = request()->get('sort');
$query = User::select(['id', 'name', 'email', 'company_id']);
switch ($sort) {
case 'github':
$query = $query->orderBy(
Github::select('name')
->whereColumn('user_id', 'users.id')
->orderBy('name')
->limit(1)
);
break;
case 'company':
$query = User::select('users.*')
->leftJoin('companies', 'companies.id', '=', 'users.company_id')
->orderBy('companies.name');
break;
default:
$query = $query->orderByDesc('id');
break;
}
$users = $query->with(['github', 'company'])->paginate(20);
return view('user.index', ['users' => $users]);
}
...
}
我们依然先通过左连接实现根据公司名对用户记录进行排序的功能:
$query = User::select('users.*')
->leftJoin('companies', 'companies.id', '=', 'users.company_id')
->orderBy('companies.name');
实现思路和一对一关联排序一模一样,只是调整了表名和关联条件而已。
现在要实现基于 Github 用户名升序排序用户记录,可以通过在 URL 请求参数中指定 sort=github:
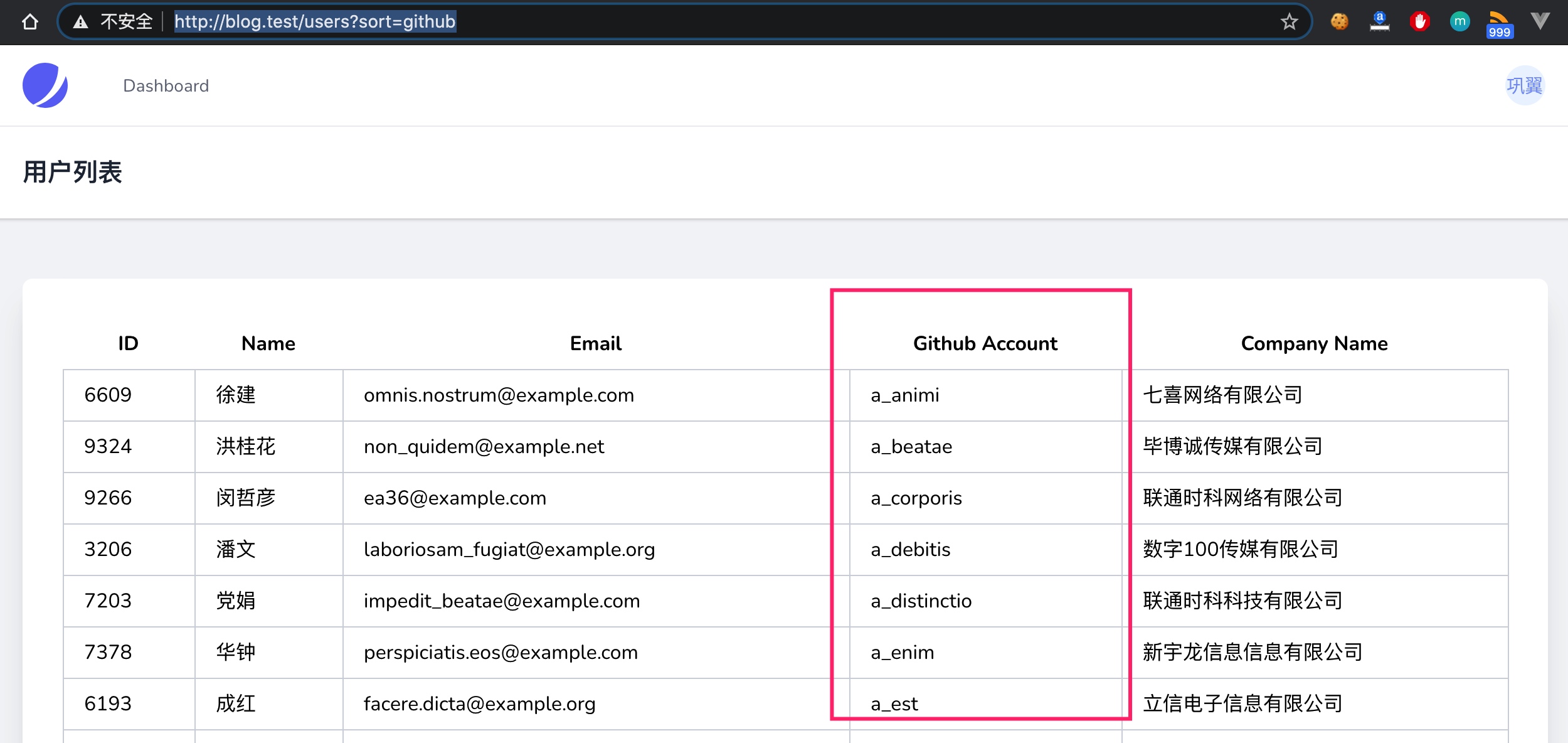
要基于公司名升序对用户记录进行排序,可以在 URL 请求参数中指定 sort=company 来实现:
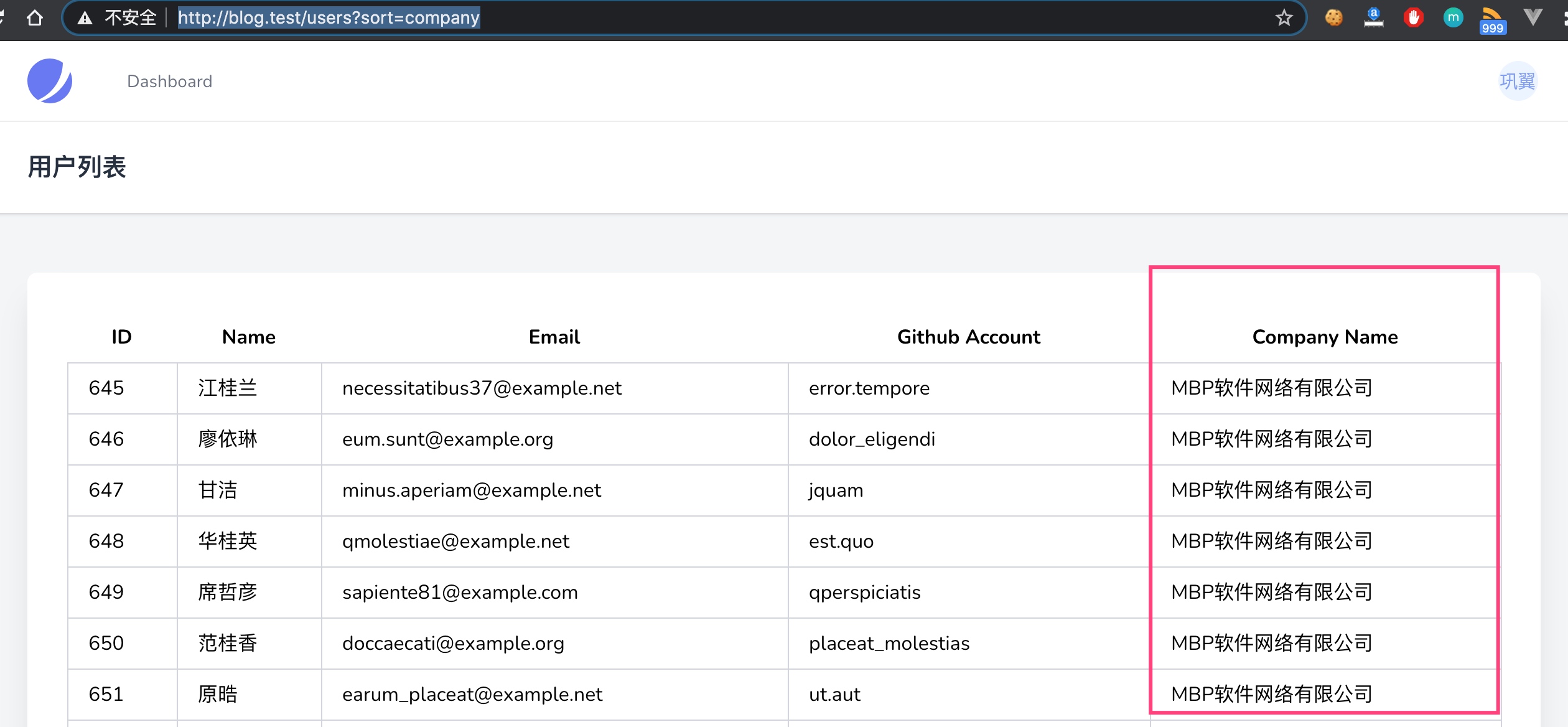
通过用户列表显示的结果,可以确定该排序功能已经正常实现,我们通过 Laravel Debugbar 工具条查看对应的 SQL 查询语句:

可以看到和一对一关联一样,查询性能并不高,因为存在全表扫描、临时表和文件排序的缘故,我们首先通过子查询实现同样的功能,看能否优化排序性能:
$query = $query->orderBy(
Company::select('name')
->whereColumn('id', 'users.company_id')
->orderBy('name')
->limit(1)
);
刷新用户列表,可以获取到上面左连接实现一样的排序结果:
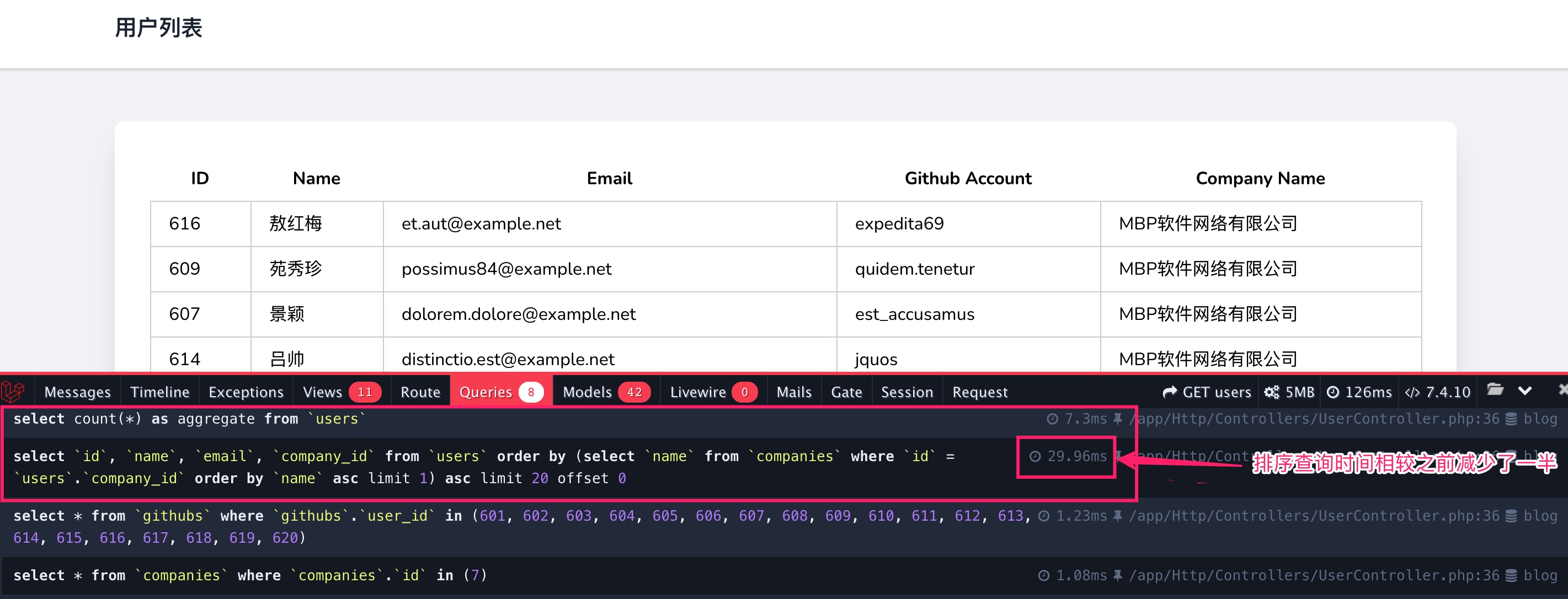
并且同样的分页排序语句查询性能优化了一倍,背后原因也和一对一关联一样,没有创建临时表。
当然,如果业务逻辑上保证了每个用户都有对应的公司,你还可以尝试通过内连接进行优化,不过这里的优化效果可能不如一对一,因为如果将公司表作为驱动表,一个公司对应多个用户,最终扫描记录也是不确定的,可能会出现还不如左连接查询性能的情况,这种情况下,子查询则变成了最优方案。
无评论