基于 Redis 实现高级限流器及其在 Laravel 队列任务处理中的应用
更高级的限流器设计
上篇教程学院君给大家演示了如何通过 Redis 的字符串数据结构实现限流器,其中需要用到两个字符串键值对:一个用于设置单位时间窗口内的请求上限,另一个用于在这个时间窗口内对请求数进行统计,当请求数超出请求上限,则拒绝后续请求。
这是一个最简单的限流器实现,其原理是通过对指定时间窗口内的请求次数上限进行限定,一旦进入的请求数超出这个限制,则拒绝后续进来的请求,而不管之前进来的请求是否已经处理完毕,讲到这里,聪明的同学可能已经想到了更高级的限流器是怎么实现的 —— 那就是引入已处理请求这个变量动态统计当前限流器内的请求总量。
在这种情况下,当新请求进来后,依然会对请求总量做自增统计,所不同的是,当之前进入的请求被处理后,则释放掉这部分的请求总量。这样一来,请求总量就不再是只增不减,而是动态变化的。
这种限流器有两种实现模式,一种依然是基于时间窗口,限定请求数上限,只不过需要额外考虑已处理的请求,这就增加了限流系统实现的复杂性。另一种是不考虑时间窗口,只考虑同时支持的并发请求上限,这种情况下的请求数上限针对的是每个时间点,而不是前一种实现针对的是整个时间窗口。
两种设计能够支持的最高并发量是一致的(假设前一个版本所有请求在同一个时间点涌入),但是显然,后一种实现的限流器大大提高了系统总的吞吐量,因为请求进进出出,只要同一时间点的总数不超过上限即可,而不是单位时间内累计的总数。
如果更抽象一点看,后一种实现的限流器是基于请求进入/处理的速率,而前一种实现则只是请求进入量的简单累加,对于后一种实现而言,只要请求处理速率高于或等于进入速率,则永远不会触发请求上限,反之如果请求处理速率低于进入速率,则累计的未处理请求总量迟早会触发请求上限。显然,通过这种限流器可以更精确地控制系统的并发访问频率。
通常,请求进入的速率都是高于请求处理速率的,这是不是像极了我们日常生活中使用的上面大而粗、下面小而细的漏斗(Funnel)?
所以后一种限流器的实现算法有一个很形象的名字 —— 漏斗算法,漏斗内液体最快的流动速率就是该限流器的最高访问频率。
Redis 高级限流器的 Laravel 实现
在 Laravel 底层的 Redis 组件库中,已经通过 PHP 代码为我们实现了这两种限流器:
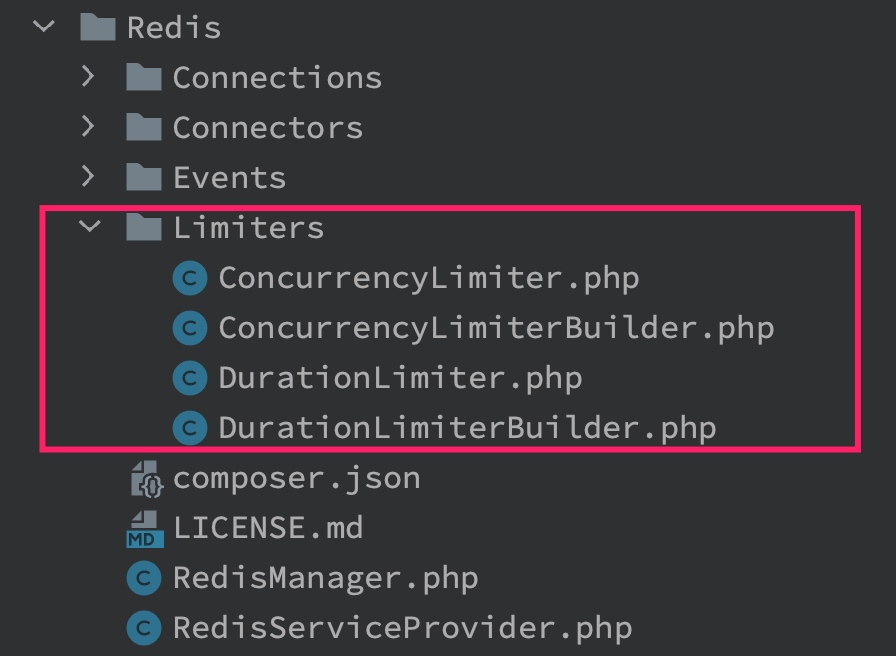
ConcurrencyLimiter是一个基于漏斗算法实现的并发请求频率限流器;DurationLimiter则是一个基于时间窗口实现的限流器,我们在上篇教程中也演示了基于 Redis 缓存驱动实现的时间窗口限流器RateLimiter,相较于DurationLimiter,它是一个非常简单的实现。
限定并发请求访问上限
下面我们通过限定用户并发访问指定控制器动作的频率来演示基于漏斗算法实现的 Redis 限流器使用。
以文章浏览这个控制器动作为例,我们要实现最多支持 100 个并发请求,可以这么做:
use Illuminate\Support\Facades\Redis;
// 浏览文章
public function show($id)
{
// 定义一个限定并发访问频率的限流器,最多支持 100 个并发请求
Redis::funnel("posts.${id}.show.concurrency")
->limit(100)
->then(function () use ($id) {
// 正常访问
$post = $this->postRepo->getById($id);
event(new PostViewed($post));
return "Show Post #{$post->id}, Views: {$post->views}";
}, function () {
// 触发并发访问上限
abort(429, 'Too Many Requests');
});
}
Redis::funnel 返回的是 ConcurrencyLimiter 限流器对应的构建器实例,然后我们通过 limit 方法指定并发请求上限,再通过 then 方法定义两个回调函数,第一个回调执行的是未触发并发上限时的正常业务逻辑,第二个回调执行的是触发并发上限后返回 429 响应的异常处理逻辑。
限定单位时间访问上限
如果想要使用基于时间窗口的限流器限定用户在单位时间内的请求上限,可以这么做:
// 定义一个单位时间内限定请求上限的限流器,每 10 秒最多支持 100 个请求
Redis::throttle("posts.${id}.show.concurrency")
->allow(100)->every(10)
->then(function () use ($id) {
// 正常访问
$post = $this->postRepo->getById($id);
event(new PostViewed($post));
return "Show Post #{$post->id}, Views: {$post->views}";
}, function () {
// 触发并发访问上限
abort(429, 'Too Many Requests');
});
这里,我们通过 Redis::throttle 方法返回 DurationLimiter 限流器对应的构建器实例,再通过 allow 指定请求上限,通过 every 指定时间窗口,这里最高支持的并发请求也是 100,但是分散到 10 秒内的累积请求上限也是 100,所以吞吐量不及上面基于漏斗算法实现的限流器。
另外,需要注意的是不同于路由限流中间件 throttle,这里的 Redis 键不是基于用户标识的,而是基于文章 ID 标识的,所以会统计所有用户针对指定文章详情页的访问次数。
ConcurrencyLimiter 的底层实现
接下来,我们沿着 Redis::funnel 去分析 ConcurrencyLimiter 限流器的底层实现源码。
Redis 门面代理的是 RedisManager 对象实例,因此 Redis::funnel 调用的是 RedisManager 对象 connection 方法返回实例上的方法,这里我们配置的 Redis 客户端是 phpredis,所以 connection 方法返回的是 PhpRedisConnection 对象实例(相关源码请阅读 Illuminate\Redis\RedisManager 底层实现代码),因此,最终调用的也是这个对象实例上的 funnel 方法(定义在其父类 Illuminate\Redis\Connections\Connection 中):

该方法返回的是 ConcurrencyLimiter 限流器对应的构建器 ConcurrencyLimiterBuilder 对象实例,我们可以在这个构建器实例上通过 limit 方法设置并发请求频率上限,再通过 then 方法定义请求处理细节:
public function then(callable $callback, callable $failure = null)
{
try {
return (new ConcurrencyLimiter(
$this->connection, $this->name, $this->maxLocks, $this->releaseAfter
))->block($this->timeout, $callback);
} catch (LimiterTimeoutException $e) {
if ($failure) {
return $failure($e);
}
throw $e;
}
}
在这里,我们会基于 Redis 连接、限流器名称、并发访问频率上限等变量值实例化 ConcurrencyLimiter 限流器实例,然后通过该实例的 block 方法传入 then 方法的第一个闭包函数定义正常请求回调代码,如果请求出现异常则执行 then 方法传入的第二个回调。
ConcurrencyLimiter 的 block 方法中包含了基于漏斗算法实现的限流器底层源码:
public function block($timeout, $callback = null)
{
$starting = time();
$id = Str::random(20);
while (! $slot = $this->acquire($id)) {
if (time() - $timeout >= $starting) {
throw new LimiterTimeoutException;
}
usleep(250 * 1000);
}
if (is_callable($callback)) {
try {
return tap($callback(), function () use ($slot, $id) {
$this->release($slot, $id);
});
} catch (Exception $exception) {
$this->release($slot, $id);
throw $exception;
}
}
return true;
}
这里,我们首先通过 acquire 方法为所有的请求槽位上锁(默认有效期是 60s):
protected function acquire($id)
{
$slots = array_map(function ($i) {
return $this->name.$i;
}, range(1, $this->maxLocks));
return $this->redis->eval(...array_merge(
[$this->lockScript(), count($slots)],
array_merge($slots, [$this->name, $this->releaseAfter, $id])
));
}
lockScript 对应的实现代码如下,就是通过一个循环结构依次为所有请求槽位上锁:
protected function lockScript()
{
return <<<'LUA'
for index, value in pairs(redis.call('mget', unpack(KEYS))) do
if not value then
redis.call('set', KEYS[index], ARGV[3], "EX", ARGV[2])
return ARGV[1]..index
end
end
LUA;
}
以后每处理完一次请求,则释放对应槽位的锁,这样,下一次请求过来就可以获取对应的锁,如果请求处理异常也释放锁。
如果用户请求进来获取锁失败,则表示所有锁都被其他请求持有,这就意味着用户并发请求已达上限,如果获取锁超时(默认超时时间是 3s),则在上一层 then 方法中捕获到超时异常,执行其第二个参数对应的异常回调函数,否则通过 usleep 方法阻塞 250ms,等待槽位空出,继续处理请求。
由于这里使用了基于 Lua 脚本的 Redis 分布式锁,所以可以保证操作的原子性。
DurationLimiter 的底层实现
基于时间窗口的限流器 DurationLimiter 对应的底层实现源码前面的流程也是和 ConcurrencyLimiter 一样的,我们直接从 then 方法开始分析,执行其第一个回调时,最终调用的是 DurationLimiter 的 block 方法:
public function block($timeout, $callback = null)
{
$starting = time();
// 获取锁操作
while (! $this->acquire()) {
// 超时抛出异常
if (time() - $timeout >= $starting) {
throw new LimiterTimeoutException;
}
// 获取失败,则阻塞 750ms 后重试
usleep(750 * 1000);
}
// 获取锁成功(还未触发上限),则执行回调函数
if (is_callable($callback)) {
return $callback();
}
return true;
}
和 ConcurrencyLimiter 类似,这里也使用了 Redis 分布式锁来确保操作的原子性。
获取锁失败时,意味着限流器已触发请求上限,没有剩余槽位可用,这个时候会先判断是否超时(默认超时时间 3s),如果超时,抛出超时异常,否则阻塞 750ms 后重试。如果获取锁成功,意味着还没有触发请求上限,则执行上一层构建器 then 方法传入的第一个回调函数。
接下来,我们来看 acquire 方法的实现代码:
public function acquire()
{
// 通过 Redis Lua 脚本设置锁,然后从返回值读取信息
$results = $this->redis->eval(
$this->luaScript(), 1, $this->name, microtime(true), time(), $this->decay, $this->maxLocks
);
// 时间窗口过期时间点(当前时间 + 传入的时间窗口大小)
$this->decaysAt = $results[1];
// 剩余支持的请求槽位(传入的请求上限 - 已处理请求数)
$this->remaining = max(0, $results[2]);
// 是否获取锁成功(基于是否还有剩余请求槽位判断)
return (bool) $results[0];
}
这里的实现并不是基于 Redis 的字符串数据结构,而是基于 Hash 数据结构,因此更加复杂一些:
protected function luaScript()
{
return <<<'LUA'
local function reset()
redis.call('HMSET', KEYS[1], 'start', ARGV[2], 'end', ARGV[2] + ARGV[3], 'count', 1)
return redis.call('EXPIRE', KEYS[1], ARGV[3] * 2)
end
-- 第一次请求会初始化一个 Hash 结构作为限流器,键名是外部传入的名称,键值是包含起始时间、结束时间和请求统计数的对象
-- 返回值的第一个对应的是是否获取锁成功,即是否可以继续请求,第二个是有效期结束时间点,第三个是剩余的请求槽位数
if redis.call('EXISTS', KEYS[1]) == 0 then
return {reset(), ARGV[2] + ARGV[3], ARGV[4] - 1}
end
-- 如果限流器已存在,并且还处于有效期对应的时间窗口内,则对请求统计数做自增操作
-- 这里,我们会限定其值不能超过请求上限,否则获取锁失败,有效期结束时间点不便,剩余槽位数=请求上限-当前请求统计数
if ARGV[1] >= redis.call('HGET', KEYS[1], 'start') and ARGV[1] <= redis.call('HGET', KEYS[1], 'end') then
return {
tonumber(redis.call('HINCRBY', KEYS[1], 'count', 1)) <= tonumber(ARGV[4]),
redis.call('HGET', KEYS[1], 'end'),
ARGV[4] - redis.call('HGET', KEYS[1], 'count')
}
end
-- 如果限流器已过期,则和第一个请求一样,重置这个限流器,重新开始统计
return {reset(), ARGV[2] + ARGV[3], ARGV[4] - 1}
LUA;
}
}
详细细节,我已经在通过注释标注了,从这个 Lua 脚本中会返回是否可以继续请求(是否可以获取锁)、有效期结束时间点和剩余可用请求槽位三个值,以便在 acquire 方法中使用。
可以看出,在 block 方法中获取锁成功并执行回调函数处理请求后,并没有重置剩余可用槽位和当前请求数统计,所以目前而言,这个限流器的功能和上篇教程实现的是一样的,如果触发请求上限,只能等到时间窗口结束才能继续发起请求。
不过,如果需要的话,你是可以在处理完请求后,去更新 Redis Hash 数据结构中的当前请求统计数的,只是这里没有提供这种实现罢了。
通过限流器限制队列任务处理频率
除了用于处理用户请求频率外,还可以在处理队列任务的时候使用限流器,限定队列任务的处理频率。这一点,在 Laravel 队列文档中已有体现。
以 PostViewsIncrement 这个队列任务为例,要限定最多支持 60 个并发处理进程,可以这么做:
public function handle()
{
Redis::funnel('post.views.increment')
->limit(60)
->then(function () {
// 队列任务正常处理逻辑
if ($this->post->increment('views')) {
Redis::zincrby('popular_posts', 1, $this->post->id);
}
}, function () {
// 超出处理频率上限,延迟 60s 再执行
$this->release(60);
});
}
和处理路由请求不同,如果触发并发处理进程上限,则使用 release 方法延迟 60s 执行这个任务。
如果想要通过时间窗口限定处理频率,比如每分钟最多执行 60 次,可以这么做:
Redis::throttle('posts.views.increment')
->allow(60)->every(60)
->then(function () {
// 队列任务正常处理逻辑
if ($this->post->increment('views')) {
Redis::zincrby('popular_posts', 1, $this->post->id);
}
}, function () {
// 超出处理频率上限,延迟60s再执行
$this->release(60);
});
如果你已经深刻洞悉对应 Redis 限流器底层的执行逻辑和实现原理,就可以驾轻就熟地使用这两个限流器来解决系统的并发瓶颈问题或者有效抵御垃圾流量。关于 Redis 限流器我们就简单介绍到这里,下一篇教程,我们一起来看看如何通过 Redis 实现用户 UV 统计功能。
2 条评论
光看文档,以为Laravel只实现了简单限流,没想到也把时间窗口和令牌桶也实现了,太方便了