基于 Redis 布隆过滤器实现海量数据去重及其在爬虫系统中的应用示例
布隆过滤器的引入
在上篇教程中,学院君给大家介绍了 UV 统计功能的实现思路,如果访问量较小,使用 SET 即可,如果访问量很大,可以使用 HyperLogLog 来降低存储空间和优化性能。
HyperLogLog 虽然强大,但是由于没有提供类似 SISMEMBER 之类的包含判断指令,所以无法实现判断某个元素是否在 HyperLogLog 中的功能,对于一些海量信息的过滤处理,比如从推荐文章中去除已读文章,从爬虫列表中去除已爬取页面等场景,则无法基于 HyperLogLog 实现。
有人可能觉得,可以通过关系数据库的字段值来实现类似的过滤功能,确实是一种解决方案,但是对于高并发请求的海量数据,数据库能否抗住这种查询压力是一个问题,即使引入了缓存,和 SET 一样,也需要大量的存储空间,并且这个存储空间会随着系统的增长不断增长。
那 Redis 是否为此提供了确保高性能的同时又减少存储空间的解决方案呢?
还真有,对于这种去重场景,我们可以使用布隆过滤器来解决,它可以用于判断某个元素是否存在于指定集合中。在确保高性能的同时,布隆过滤器能够将存储空间降低 90% 以上,不过和 HyperLogLog 一样的问题是,它也存在一定误差,不过对于海量数据而言,这个误差是可以接收的。
启动包含布隆过滤器的 Redis 服务器
布隆过滤器并不是 Redis 创造的,而是 1970 年由布隆提出的一种过滤器,其英文名称是 Bloom Filter,Redis 官方提供的布隆过滤器要到 Redis 4.0 提供了插件功能之后才能使用 —— 布隆过滤器会作为一个插件加载到 Redis 服务器中,给 Redis 提供了布隆去重功能。
这里为了简化流程,我们通过 Docker 镜像来快速搭建包含布隆过滤器的 Redis 服务器:
redis:
# image: 'redis:alpine'
image: 'redislabs/rebloom:latest'
ports:
- '${REDIS_PORT}:6379'
volumes:
- './docker/data/sailredis:/data'
networks:
- sail
注:将
docker-compose.yml中之前的redis镜像替换成redislabs/rebloom,然后重启构建镜像并启动 Redis 服务器即可,客户端代码不用做任何调整。
接下来,我们就可以在 Redis 中使用布隆过滤器了。
布隆过滤器的基本使用和底层实现
基本使用
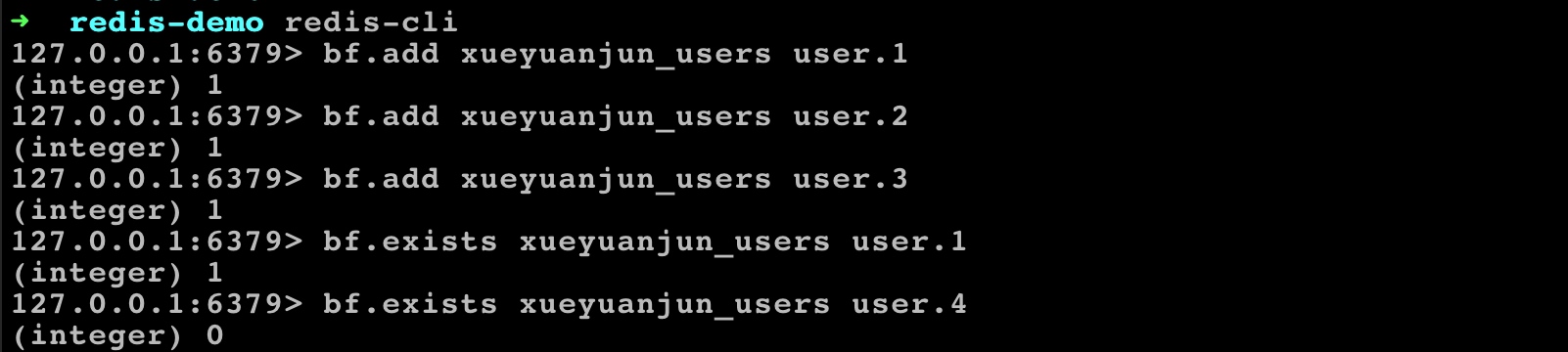
我们可以通过 bf.add 指令添加元素到集合,使用 bf.exists 检查元素是否存在:
当然,也可以通过 bf.madd 指令批量添加元素到集合,然后使用 bf.mexists 检查多个元素是否存在:

要删除布隆管理器集合,使用 Redis
DEL指令即可。
底层原理
可以看到布隆过滤器的指令和 SET 结构支持的指令非常类似,其实你也可以将布隆过滤器看做不太精确的 SET 结构,不过布隆过滤器存在误差:它判断不存在的元素,一定不存在,但是它判断存在的元素,有可能不存在。
上述示例没有误差是因为数据量很小,你可以参考上篇教程 HyperLogLog 数据填充验证数据量变大之后的误差情况。
要解释这个误差存在的原因,需要先了解布隆过滤器的底层实现。
每个布隆过滤器对应到 Redis 底层的数据结构就是一个大型的位数组和一系列的无偏哈希函数(所谓无偏就是能够把元素的哈希值算得比较均匀):

向布隆过滤器中添加键值对时,会使用这一系列哈希函数分别对键名进行哈希运算,然后将得到的整数索引值与位数组长度进行取模运算得到最终索引位置,再把位数组的这几个索引位都置为 1,这就完成了 bf.add 操作。
向布隆过滤器查询指定键名是否存在时,和 bf.add 一样,也会把哈希后的索引位置都算出来,看看位数组中这几个索引位的值是否都为 1,只要有一个位为 0,则说明布隆过滤器中这个键名不存在。如果都为 1,也并不能说明这个键名就一定存在,只是很有可能存在,因为这些位被置为 1 可能是其它键名哈希运算时出现哈希冲突所致(概率很低,但是存在)。
如果这个位数组比较稀疏,判断正确的概率就会很大,如果这个位数组比较稠密,判断正确的概率就会降低,因为出现哈希冲突的概率会提高,但是相对整体而言依然是很小的比例。
自定义布隆过滤器参数
实际使用时,如果需要的话,可以通过在 bf.add 之前执行 bf.reserve 指令自定义布隆过滤器的参数,这个指令支持三个参数:
key:指定键名;error_rate:错误率,默认是 0.01,即 1%,你可以将其调小,但是错误率越低,所需要的集合容量就越大,占用的存储空间就越大;initial_size:初始化的集合容量(集合中存放的元素数量),默认是 100,该值越大,错误率越低,但所需的存储空间也就越大,反之该值越小,所需的存储空间越小,但错误率越高。
布隆过滤器在爬虫系统中的应用
通过上面的分析,我们可以得出这个结论:布隆过滤器判断不存在的元素一定不存在,而布隆过滤器判断存在的元素则不一定存在(概率很低,误差默认小于 1%)。
因此,布隆过滤器非常适用于做海量数据的去重,比如一个爬虫系统,需要爬取数百万乃至上千万甚至上亿的链接,当拿到一个链接进行爬取前,先要判断这个链接是否已经爬取过,如果没有才进行爬取,以免浪费系统资源,通过布隆过滤器很容易实现这个功能:通过 bf.exists 命令判断链接不存在,则进行爬取,否则不爬取。
这种情况下,需要爬取的肯定都是没有爬取过的链接(布隆过滤器说不存在就一定不存在),没爬取的则可能会存在少量的未爬取链接被忽略(布隆过滤器说存在,则可能不存在),不过这个比例很低,你也可以通过 bf.reverse 进行进一步的调优。尽管存在一定误判,但是能够保证爬虫系统可以正常运行,对我们来说,需要优先保证的是爬取未爬取的链接,对于极小部分的链接被忽略,则不影响整体功能的可用性。
接下来,我们在 Laravel 中演示如何实现这个功能。
安装 phpredis-bloom 扩展包
phpredis 客户端默认是不支持布隆过滤器指令的,需要安装如下这个扩展包才可以在 PHP 客户端中使用布隆过滤器:
sail composer require averias/phpredis-bloom
模型类、数据表准备
开始之前,先创建爬虫对应的模型类和数据表迁移文件:
sail artisan make:model CrawlSource -m
编写刚生成的数据表迁移文件代码如下:
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
class CreateCrawlSourcesTable extends Migration
{
public function up()
{
Schema::create('crawl_sources', function (Blueprint $table) {
$table->id();
// 爬取 URL
$table->string('url');
// 爬取状态
$table->tinyInteger('status')->unsigned()->default(0);
$table->timestamps();
});
}
public function down()
{
Schema::dropIfExists('crawl_sources');
}
}
运行 sail artisan migrate 在数据库中创建这张数据表,然后创建 CrawlSource 模型类对应的模型工厂定义填充字段:
sail artisan make:factory CrawlSourceFactory
编写 CrawlSourceFactory 类的 definition 方法如下:
public function definition()
{
return [
'url' => $this->faker->url,
];
}
注:这里我们没有设置唯一性,所以生成的链接可能会重复。
然后修改数据填充器类 DatabaseSeeder 的 run 如下:
public function run()
{
\App\Models\CrawlSource::factory(10000)->create();
}
运行数据库填充命令 sail artisan db:seed 为 crawl_sources 表插入 10000 条记录。
为了验证 crawl_sources 中包含重复的 URL,可以运行这个 SQL 查询:
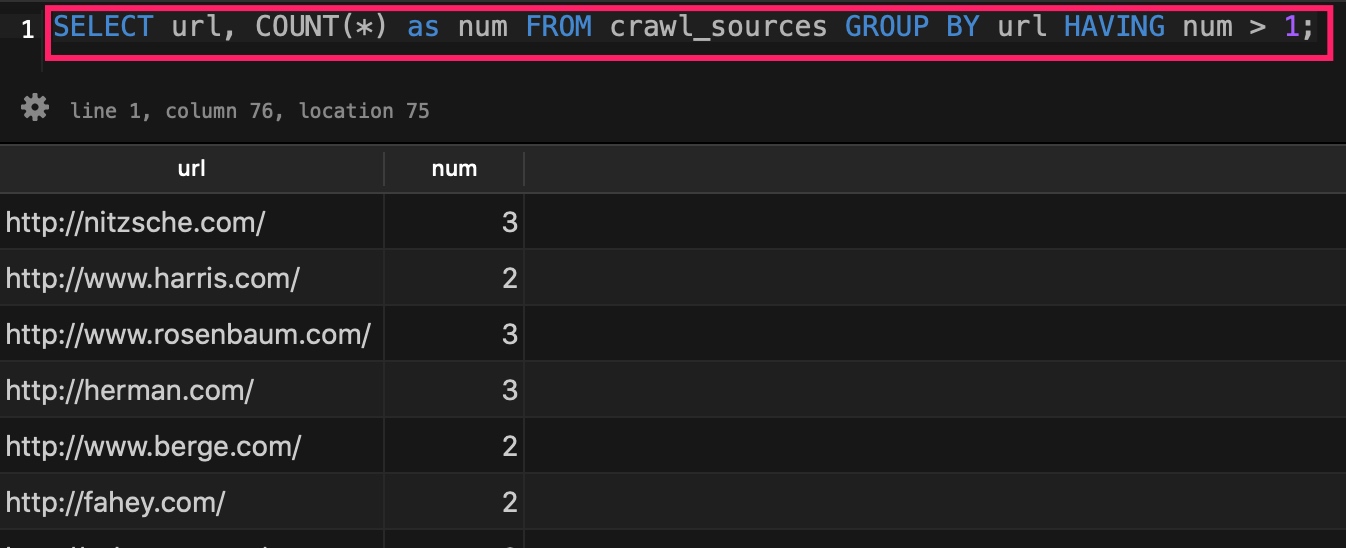
结果集不为空,则表示存在重复的 URL。如果结果集为空,你可以继续运行数据库填充命令,或者手动设置一些重复记录。
编写爬取 URL 任务类
接下来,创建一个爬取 URL 的队列任务:
sail artisan make:job CrawlUrl
编写 CrawlUrl 类实现代码如下:
<?php
namespace App\Jobs;
use App\Models\CrawlSource;
use Illuminate\Bus\Queueable;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Foundation\Bus\Dispatchable;
use Illuminate\Queue\InteractsWithQueue;
use Illuminate\Queue\SerializesModels;
class CrawlUrl implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
public CrawlSource $crawlSource;
public function __construct(CrawlSource $crawlSource)
{
$this->crawlSource = $crawlSource;
}
public function handle()
{
sleep(1); // 模拟爬取 URL 操作
$this->crawlSource->status = 1;
$this->crawlSource->save();
}
}
这里我们将判断是否爬取工作放到上层业务代码,CrawlUrl 只专注于爬取 URL 工作,以避免占用额外的队列系统空间、提升对系统资源的利用率。
通过队列处理 URL 爬取工作
最后,创建一个 Artisan 命令来推送爬取 URL 工作到队列:
sail artisan make:command StartCrawlUrls
编写这个 StartCrawlUrls 命令类代码如下:
<?php
namespace App\Console\Commands;
use App\Jobs\CrawlUrl;
use App\Models\CrawlSource;
use Averias\RedisBloom\Client\RedisBloomClientInterface;
use Averias\RedisBloom\Enum\Connection;
use Averias\RedisBloom\Exception\RedisClientException;
use Averias\RedisBloom\Factory\RedisBloomFactory;
use Illuminate\Console\Command;
class StartCrawlUrls extends Command
{
protected $signature = 'start:crawl';
protected $description = 'Start Crawl Urls';
protected RedisBloomClientInterface $redisClient;
public function __construct()
{
$factory = new RedisBloomFactory([
Connection::HOST => config('database.redis.default.host'),
Connection::PORT => intval(config('database.redis.default.port')),
Connection::DATABASE => intval(config('database.redis.default.database'))
]);
$this->redisClient = $factory->createClient();
parent::__construct();
}
public function handle()
{
$key = config('app.name') . '.bf.crawls';
CrawlSource::chunk(100, function ($sources) use ($key) {
foreach ($sources as $source) {
if ($this->redisClient->bloomFilterExists($key, $source->url)) {
$this->info('Processed: ' . $source->url);
} else {
CrawlUrl::dispatch($source)->onQueue('crawler');
$this->redisClient->bloomFilterAdd($key, $source->url);
}
}
});
$this->info("\n所有任务推送完毕!");
}
}
这里我们在首次爬取某个 URL 时通过 RedisBloom 提供的 bf.add 指令将其添加到布隆过滤器集合(这里没有误差),如果通过 bf.exists 判断某个链接已处理,则跳过(这里可能存在一定误差)。
运行 sail artisan start:crawl 推送任务到队列,这个时候可以看到 Processed 日志输出,表明布隆过滤器已经介入并进行了去重操作,运行完成后,通过如下命令启动队列处理器进程消费队列:
sail artisan queue:work --queue=crawler --tries=3
如果你想要要加速队列处理速度,可以启动多个处理器进程。
你可以在队列任务处理完成后,比对 crawl_soources 中的唯一 URL 总数和已爬取 URL 总数来看看误差是多少,我这里这个两个数值分别是 9417/9327,误差率在 1%,和默认值相符,对于爬虫而言,这个误差率还是有点高的,你可以参考上面介绍的自定义配置对参数进行调优,再看看误差率是否得到了优化。
其他使用场景
除了爬虫链接去重之外,布隆过滤器还可以广泛应用于推荐系统去重(比如电商推荐系统排除已购买过的商品)、敏感词过滤系统(敏感词库是否已包含这个敏感词)、垃圾邮件/短信过滤(判断某个邮箱是否是垃圾邮箱)、避免缓存穿透(将缓存键放到布隆过滤器,避免恶意读取不存在的缓存键对 DB 造成巨大压力)等业务场景,这里就不一一介绍了,有需要的同学可以在自己的系统中使用布隆过滤器去实现。
2 条评论
应该是应用在缓存穿透,不是缓存击穿上,两者有区别
嗯 是的 我改下