业务流量峰值检测和数据一致性
业务流量有尖峰听起来不错,但是当尖峰到来时需要通知开发者以便有足够的资源(CPU、内存等)应对。
检测流量尖峰并发送通知
假设我们是一个监控平台,现在我们的需求是,需要为所有站点用户发送流量尖峰警告,基本实现代码如下:
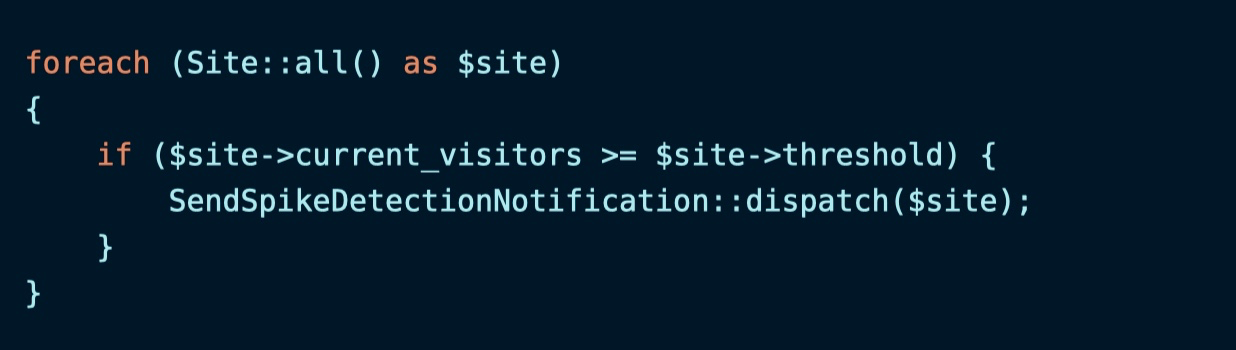
这里的 $site->current_visitors 表示站点当前访问量,$site->threshold 表示该站点设置的警告阈值,当访问量超过阈值,则发送尖峰预警通知(推送到消息队列异步执行)。这段代码需要作为 CRON 任务每分钟调度一次,以便持续检测流量尖峰。
发送流量尖峰通知的任务类代码如下,这里我们发送的是短信通知:
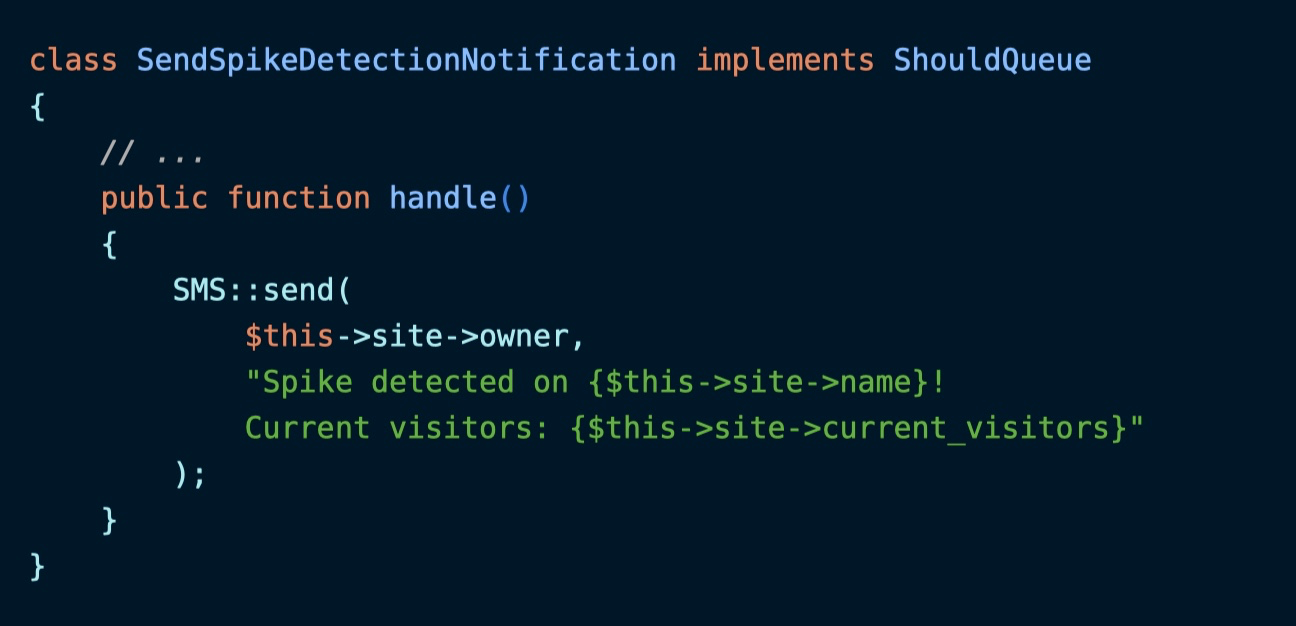
但是,如果队列很繁忙的话,当用户收到通知时就有延迟了,此时的流量和当时并不一样。如果用户设置的阈值是 100000,发送消息时可能变成了 70000,这会导致用户很困惑,觉得我们的监控系统有问题。
优化流量预警数据延迟问题
模型序列化
这是因为 Laravel 默认会在执行队列时重新查询数据库获取最新数据。
当我们推送任务到队列时,data.command 字段存储的实际上是序列化之后的 SendSpikeDetectionNotification 对象:

这个序列化版本的对象持有的 site 属性也不是 App\Site 模型实例,而是 ModelIdentifier。ModelIdentifier 是一个持有模型信息的简单对象,队列处理器从队列获取到这个任务类进行处理时,会通过这些模型信息再去数据库查询对应的模型实例。
Laravel 这么做的原因主要是减小载荷数据的大小,防止在模型序列化和反序列化时出现问题。
这些底层实现源码位于
SerializesModelsTrait 中,感兴趣的同学可以自行去查看。
让任务类自给自足
现在我们了解了消息队列中模型序列化是怎么做的了,每次从队列中取出任务类时,如果持有模型属性,则需要重新执行数据库查询获取最新值。此时的模型状态可能和推送任务类时不一样了。
要避免上面出现的数据延迟问题,必须让任务类可以做到「自给自足」:对于一些可能变动的模型属性,在推送任务时就通过传参将其固定下来,这样在处理任务类时使用的值和推送时就一致了。
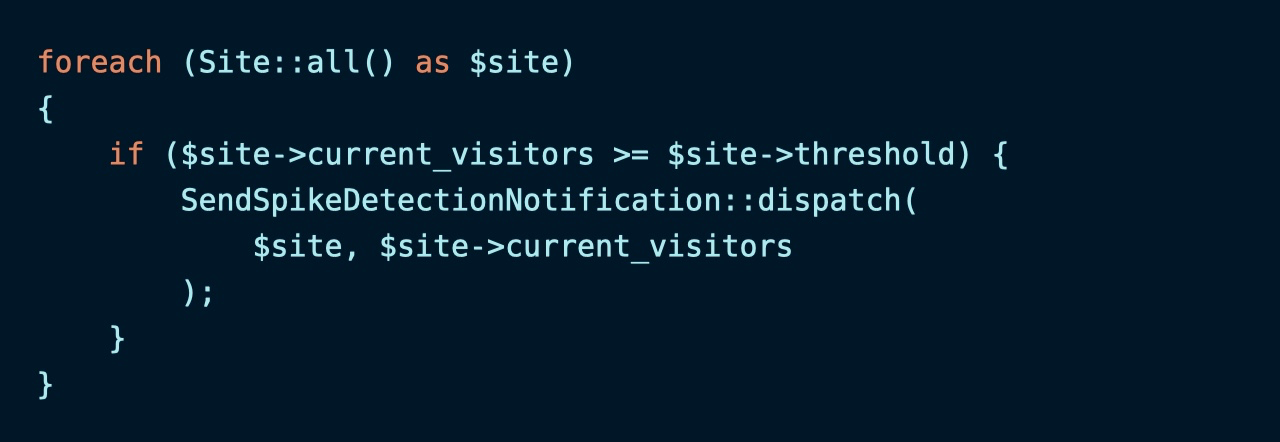
修改任务类如下,新增 visitors 属性:
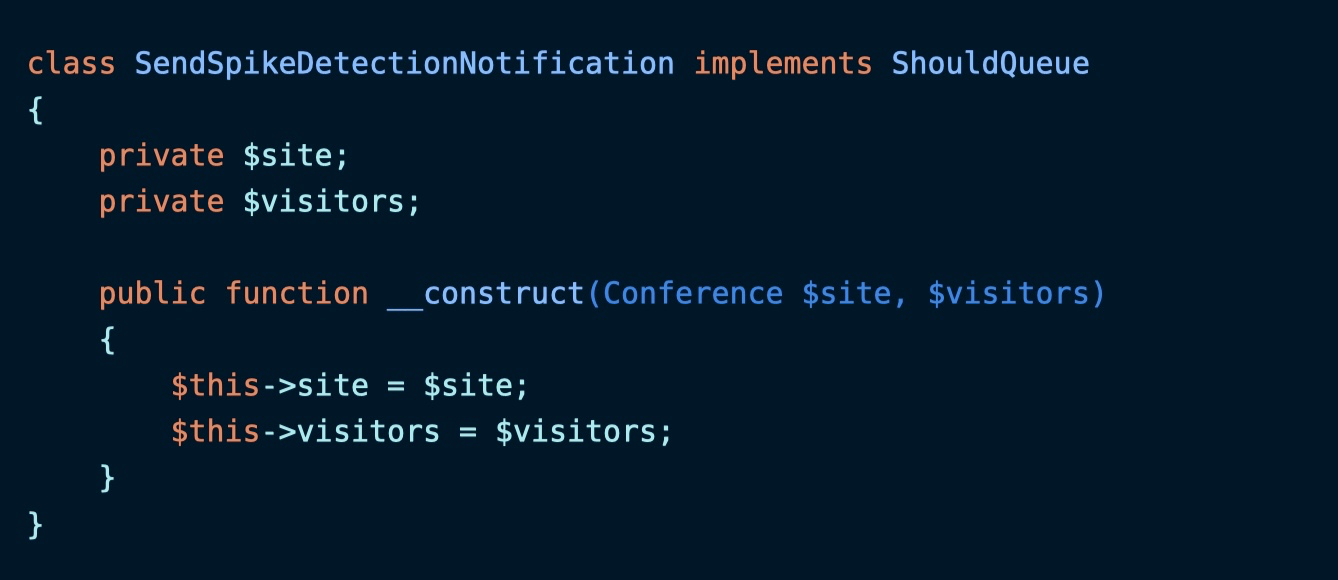
这样一来,序列化版本的任务数据就包含 ModelIdentifier 和 visitors 了。我们可以在 handle 方法中直接使用 visitors 属性获取推送任务时的流量:
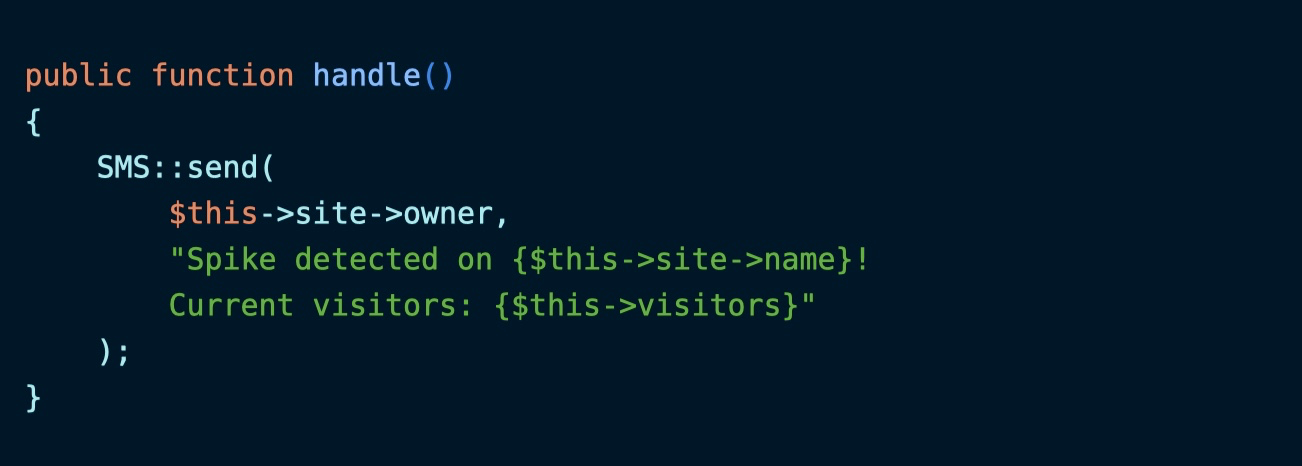
就做到前后一致了,用户在收到通知后,也不会再有明明没有达到阈值,却发送警告通知的困惑了。
无评论