处理队列任务生命周期的所有失败
队列系统引入了 3 个角色:
- 生产者:推送消息到队列;
- 消费者:从队列读取消息并处理;
- 存储器:存储消息。
任何角色或者通信通道出现问题都可能导致任务处理出错。比如存储器崩溃(Redis)、处理器处理任务中途出错。为了保证系统状态的一致性,需要处理好这些错误。
序列化任务失败
队列任务被推送到消息队列前,先要进行序列化操作。任务对象必须可以被序列化为字符串格式:
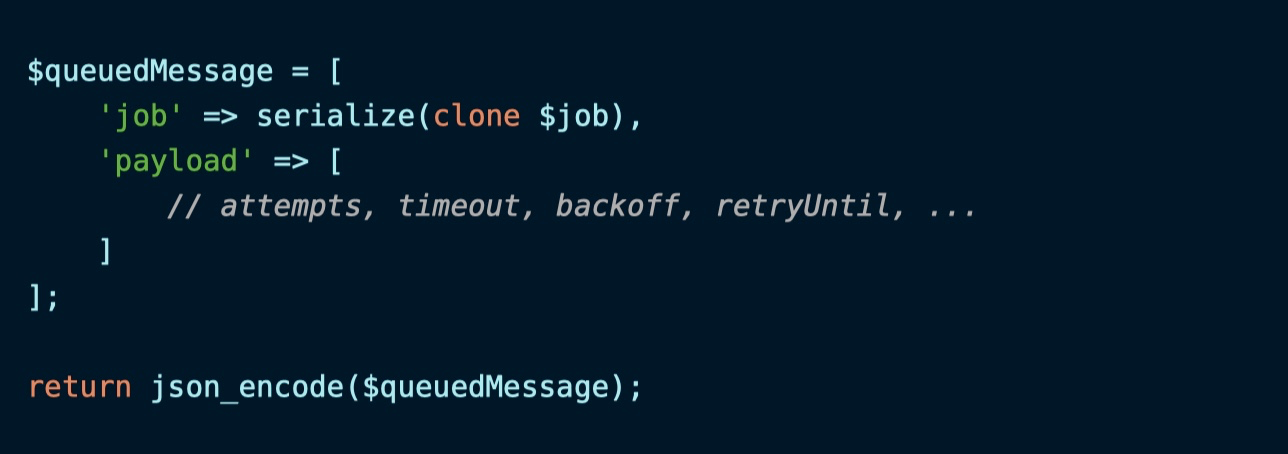
如果对象序列化或者 JSON 编码过程中出错,就会抛出异常,该任务将不会被推送到队列。要消除这种失败,需要确保任务类及其依赖都可以被序列化。
发送任务失败
如果任务对象序列化成功,接下来的错误点就是发送任务到队列,这里可能出现的 问题是队列任务载荷数据过大,或者网络问题。
一些队列驱动对载荷数据大小有限制,比如 SQS 限定消息尺寸不能超过 256 KB。所以我们要确保队列任务尽可能简单。
至于网络问题,需要引入重试机制:

这里,我们设置间隔 5s 后重试。有的时候,立即重试效果更好,比如 SQS,但是对于其他队列驱动,如 MySQL、Redis,可能需要更长时间恢复。
死信队列(Dead Letter Queue)
所谓「死信」是指未投递的邮件,如果我们把推送到消息队列的任务对象看作邮件的话,客户端死信队列则是生产者端的队列存储器,它会在这里保存被「退信」的队列任务。
一些队列任务不是那么重要,如果推送失败,可以由终端用户后续再次触发重新推送;一些队列任务则很重要,即使没有终端用户介入,也必须最终推送到消息队列。
以 GenerateReport 任务为例,如果执行失败,用户会收到报错信息,可以再次点击生成报告按钮执行它。而订单生产后执行的 SendOrderToSupplier 任务则必须能够自动重新执行。
下面来看一个简单的客户端私信队列:
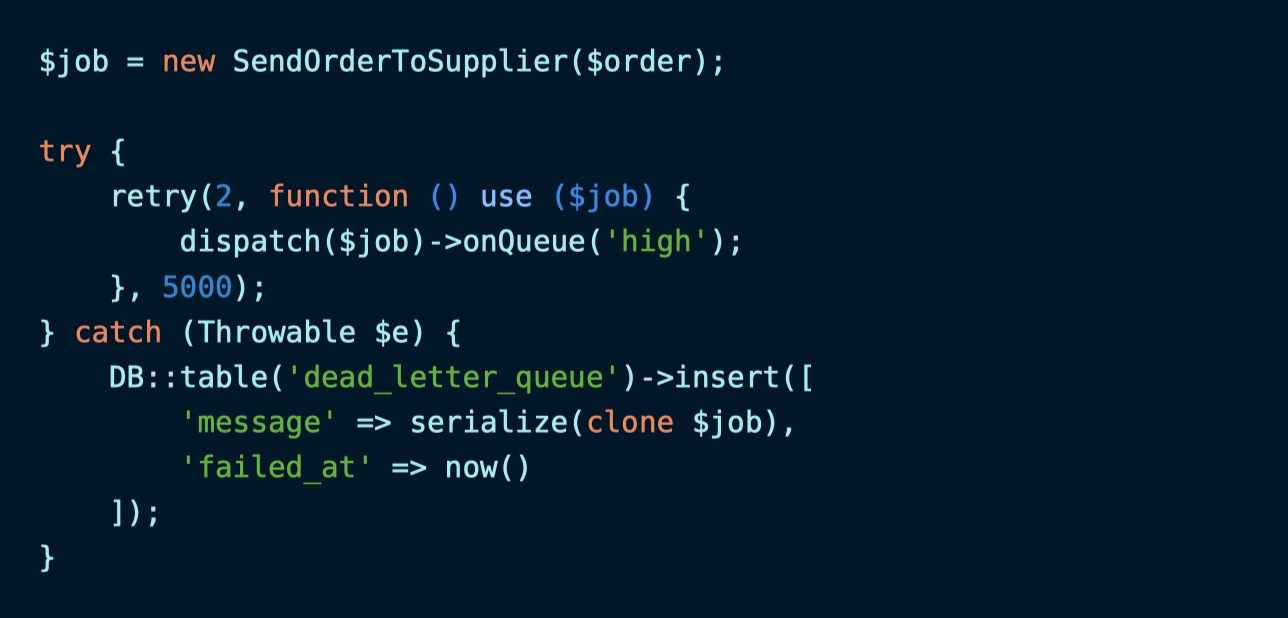
这里我们会将发送失败的队列任务存储到 dead_letter_queue 数据表,然后设置一个 CRON 调度任务周期性地检查这张数据表,以便重新推送这些「死信」:
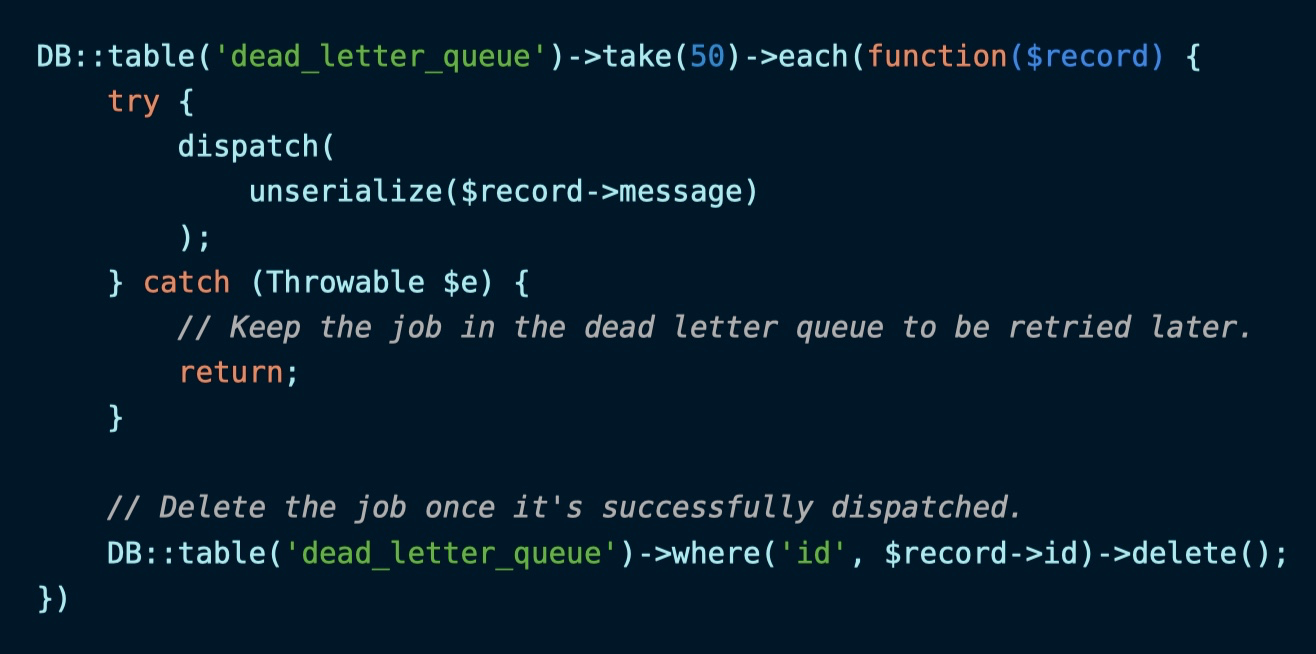
获取任务失败
一旦任务到达队列存储器,处理器就会开始获取任务进行处理。如果处理器在尝试获取队列任务时遭遇失败,就会报告一个异常,这时处理器会暂停一秒再重试。
如果你使用了像 Flare 或 Bugsnag 这样的错误跟踪器,当处理器开始抛出异常时,你会收到提醒。这种情况下,你可能需要修复队列存储侧的连接问题,或者完全关闭处理器进程,直到连接恢复,这样就不会浪费 CPU 资源。
如果使用数据库作为队列驱动,Laravel 会在检测到数据库连接错误后自动退出处理器进程。
运行任务失败
获取到队列任务后,最后就是执行环节了。导致队列任务执行失败的原因有多个:
- 抛出异常
- 任务超时
- 服务器崩溃
- 处理器进程崩溃
每次队列任务执行失败,都会消耗一次尝试次数(如果配置了的话)。如果触发了尝试次数上限,会抛出最大尝试次数耗尽异常。或者如果队列任务配置了过期时间,该任务会从消息队列中删除,处理器进程也不再尝试执行它。
你可以在 failed_jobs 数据表中看到所有执行失败的任务,还可以通过 queue:retry 重试指定任务:

或者重试所有任务:

在 failed_jobs 数据表中,你还可以看到队列任务执行失败的异常原因,如果看到类似这样的异常信息:

可能是这些原因导致的:
- 队列任务在最后一次尝试时超时;
- 队列任务最后一次执行期间服务器/处理器进程崩溃;
- 队列任务最后一次执行期间被推送回消息队列;
retry_after配置值小于任务超时时间,从而导致最后一次执行期间,又创建了一个新的队列任务实例,要避免这个场景发生,需要确保queue.php配置文件中的retry_after连接配置大于所有任务的超时时间。
无评论